Wybór konkretnej liczby rekordów z dużego zestawu jest dobrym pomysłem, ale kiedy zestaw jest naprawdę duży, pojawia się efekt pogarszania idei. Wybór wielu pozycji z określonej pozycji powoduje prawdziwy spadek wydajności: przed osiągnięciem celu MySQL przegląda inne wpisy, poświęcając na to czas.
Formalnie, limit MySQL może działać od początku tabeli lub od jej końca. Pobieranie próbek może określać określoną liczbę wpisów rozpoczynających się od danej pozycji. Zawsze może być jakiś incydent, to znaczy początek najgorszej sytuacji jest możliwy. Zazwyczaj ogólny przepływ klientów określa ogólny tryb statystyczny działania, ale aby przewidzieć różne sytuacje, konieczne jest podjęcie poważnej decyzji na korzyść strony.
LIMIT strukturalny
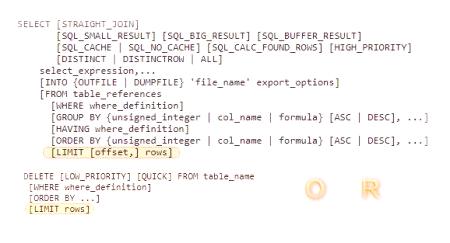
W oficjalnych źródłach, składnia limitu MySQL jest zaznaczona, jak pokazano na poniższym obrazku w kontekście zapytań wyboru i usuwania.
Przykładowe żądanie (wybierz) obejmuje dwie liczby: przesunięcie "O" i "R", żądanie usunięcia jest zapisywane za pomocą jednego numeru - liczba pozycji "R" jest usuwana.
Duże wartości limitu "O, R"
Limit MySQL: składnia pozwala na wybór wartości w dowolnym schemacie. Warunki podstawowe: "O" jest przesunięciem pierwszego wybranego rekordu, "R" jest liczbą wybranych pozycji. Problem polega na tym, że jeśli "O" = 9000, zanim MySQL wybierze rekord 9001, przejdzie przez pierwsze 9000. Jeśli R = 1000, wtedy całkowita próbka "zajmie" 10 000 rekordów. Limit wyboru MySQL może działać od początku tabeli lub od jej końca, w zależności od kierunku sortowania rekordów asc /desc. Możliwość pracy od końcaTabele nie są obiecującym rozwiązaniem, chociaż w niektórych sytuacjach trudno się bez niego obejść.
Projekt, w którym duże "R" byłoby mało interesujące dla programisty i użytkownika: limit usuwania MySQL. I to daleko od wszystkich przypadków. W tym projekcie główny ciężar odpowiedzialności spoczywa na stanie próbki (gdzie) usuniętych rekordów. W celu zapewnienia bezpieczeństwa i kontroli procesu usuwania rekordów programista zazwyczaj jest zainteresowany wykorzystaniem mechanizmu AJAX i usuwaniem rekordów w małych porcjach. Dzięki takiemu mechanizmowi odwiedzający witrynę nie zauważy opóźnień w projektowaniu usunięcia.
Próbka według jednego unikalnego rekordu
Poprawny warunek gdzie i zapytanie "limit 1" MySQL zostanie wykonane natychmiastowo. Jednak usunięcie lub wybranie jednego wpisu nie zawsze jest dobrą decyzją. Zazwyczaj przyrostowe próbkowanie dla wszystkich pozycji w tabeli służy do organizacji danych strony (na przykład komentarze, artykuły, recenzje produktów). Decyzja o budowie zawartości strony powinna być natychmiastowa, ale przy klasycznym zastosowaniu limitu MySQL O, R będzie szybko wybierany tylko z pierwszych dziesięciu z pierwszych setek rekordów, a następnie zacznie się opóźniać. Tymczasem nie wszystko jest takie trudne, możesz szybko wybrać nagranie, ale wygrać dzięki projektowi i logice wyprowadzania rekordu do przeglądarki odwiedzającego.
Nic nie stoi na przeszkodzie, aby było spektakularne i ukrywało śmiertelne opóźnienie w dialogu tworzenia treści.
Relacja relacyjna w MySQL
MySQL jest doskonałym narzędziem do prezentacji i przetwarzania informacji. Deweloper ma dobrą dialekt językaSQL i wygodny mechanizm do tworzenia zapytań. Błędy i nieprzewidziane sytuacje są rejestrowane, dostęp do danych jest administrowany do poziomu podstawowych operacji. Wszystkie wady odnoszą się do samej koncepcji stosunków relacyjnych. Co zrobić, ta koncepcja działa tak fundamentalnie i niezawodnie, że nie pozostaje nic innego, jak wziąć pod uwagę jej specyfikę i wziąć je pod uwagę. Obecny poziom rozwoju sprzętu, wysokiej jakości implementacja funkcjonalności wszystkich narzędzi MySQL (limit nie jest wyjątkiem) zapewnia dostępność dużych wolumenów danych przy dużych prędkościach i, co najważniejsze, samplingu.
Duże woluminy i standardowa pamięć podręczna
Buforowanie danych przed nagraniem i po pobraniu próbek - pomysł jest wspaniały, ma swoje korzenie w odległych latach 80-tych. Buforowanie stało się modne na wszystkich poziomach przetwarzania danych od procesora, sieci, do, oczywiście, poziomu serwera http i faktycznie baz danych. Deweloper może skontaktować się z administratorem serwera lub skonfigurować buforowanie na poziomie Apache i MySQL lub inną kombinację oprogramowania używaną do zapewnienia działania zasobu sieciowego i serwera MySQL.
To normalne, standardowe rozwiązanie. W większości przypadków jest to zwyczajowe. W programowaniu, długo poszukiwana idea podziału pracy. Programista tworzy witryny, administrator zarządza pracą wszystkiego, co zapewnia optymalizację korzystania z witryny. W krytycznych sytuacjach, gdy tabele bazy danych są duże, muszą odejść od przyjętych kanonów. Musisz coś zmienić w organizacji danych.
Tablichnaorganizacja stronicowania
Twórcy są przyzwyczajeni do: relacyjnej bazy danych - zbiór tabel powiązanych ze sobą na klawiszach. Taki prosty pomysł, stół reprezentował masę podobnych stron o tej samej nazwie, ale różnych wskaźników, które wykraczają poza zwykłą prezentację.
Ale co tu jest zabawne? Tabela to zbiór rekordów zawierających różne dane, odpowiadający rodzajom pól (kolumny, nagłówki tabel). Zapytanie MySQL granica zapytanie odnosi się do tabeli „big_info” i wybiera c 100000 pozycjach 24 linia wyświetlacza w przeglądarce. W tej decyzji w próbce bierze udział 100024 linii - to bardzo długo. Jeśli jednak zmienić tę sytuację i cały stół „big_info” malować kilkaset tabel „big_info [0999]” z 1000 rekordów, problem pojawia się tylko wtedy, gdy poproszony MySQL „zamówienie * krańcowego O, R”, ponieważ sortowania będzie niezwykle trudne. Jednak nie tylko porządek, ale wszelkie inne zapisy transakcyjne wszystko znaczy niemożliwą powyższa tabela bazy danych, która jest reprezentowana przez kilku tabelach. W tym kontekście nie ma indeksu w MySQL. Relacje relacyjne zapewniają klarowność: istnieje baza danych, tabele, tabele - kolumny i rekordy. Cóż, są "balsamy": procedury przechowywane, wyzwalacze, warunki i inne szczegóły.
i własną pamięć podręczną znaczy
Dobry pomysł „Yandex” - „termiczny”: ciepła mapy internetowej. To narzędzie pokazuje w decyzji o kolorze spektralnym rozkład istotności odwiedzających na "terytorium" strony. Najwyraźniej wkrótce pojawi się nowy przedmiot szkolny - geografia strony: gdzie i co umieścić. Dobry dodatek do generałageografia Pomysł ten, przetłumaczony na terytorium rekordów dużych tabel bazy danych, pozwala nam sformułować obiektywną tezę: nie całe terytorium rekordów jest popytem i nie zawsze.
Im większy przepływ odwiedzających, tym więcej prawidłowości do potrzeb próbki. Limit MySQL jest zawsze wykonywany dokładnie i zawsze z konkretnego powodu. Zbieranie konkretnych powodów nigdy nie zadziała. Z każdego powodu limit MySQL w każdym przypadku jest banalny. Okazuje się, że nie jest to tabela organizacji stron w formacie setek podobnych stron i stożek zapotrzebowania na informacje. Tylko w przypadkach śmiertelnych lub podczas wchodzenia na stronę informacyjnego gościa jest próbka dużej ilości danych. Zwykle - wybrane są żetony. Własna pamięć podręczna w sposób elementarny rozwiązuje problem prędkości: próbka trafia do klucza "konkretna przyczyna" z małej tabeli wyników ostatnich operacji próbki z jednej dużej tabeli.
Sortowanie i inne operacje hurtowe
Problem dużych ilości danych zależy od wydajności sprzętu komputerowego. Dzisiaj osiągnięto olbrzymi poziom wydajności, ale ilość danych również gwałtownie wzrosła. Kiedy prędkość i jakość dróg wzrasta, potrzeba szybkiego przemieszczania się i natychmiastowego rozwiązywania zadań jest odpowiednio zwiększana. Prosta operacja sortowania, zapisu lub wyszukiwania wpływa bezpośrednio lub pośrednio na wszystkie rekordy dużego stołu - potencjalny hamulec, gwarantowana utrata wydajności.
Relacyjnezwiązek był zbyt długi dla dłoni mistrzostw, ale ustąpienie po dziś dzień nie miało intencji: po prostu nikomu. Inne warianty organizacji danych, które zapewniają natychmiastową nawigację na dużych ilościach informacji, nawet nie wymyśliły super-lidera branży "Świetna informacja" - Oracle. Ale Oracle zapewnia dobre doświadczenie i doskonałą wiedzę w zakresie implementacji języka SQL i jego dialektów. W funkcji MySQL ma pewne piętno jakości. Deweloper może bezpiecznie korzystać z projektu limitu MySQL na jednej tabeli danych i mieć swobodny dostęp do operacji hurtowych na tym dużym stole.
Naturalne postrzeganie informacji
Dana osoba postrzega i przetwarza, w dużej mierze nieświadomie, ogromną ilość informacji, która nie jest dostępna dla najbardziej zaawansowanych narzędzi Oracle. Ale nie może być z tego szczególnie dumny. Oracle może migrować takie ilości danych i wykonywać takie sortowanie, które wymaga wykonania ponad stu przypadków ludzkiego życia.
Każdy musi wykonywać swoją pracę i robić to w najbardziej efektywny sposób. Postawy relacyjne nigdy nie zostaną usunięte - są one charakterystyczne dla danych, stanowią integralną ich część. Ale implementacji baz danych w relacjach relacyjnych brakuje semantyki. Kluczową organizacją, indeksy dostępu do rekordów, nie jest zawartość zapewniająca szybki dostęp do informacji. Konsekwentna organizacja pamięci maszyny i emulacja asocjacyjnego dostępu do informacji - prawdziwa przyczyna utraty czasu podczas uzyskiwania dostępu do dużego stołu w celu wypróbowania informacji przy zachowaniu zgodności z niąintegralność operacji grupowych.
Obiekty informacyjne i naturalne stowarzyszenia
Unikaj sekwencji w realizacji operacji, których programista nie może jeszcze wykonać. Tak zorganizowany świat komputerowy. Komputer ma jeden procesor oraz warianty wielordzeniowe i wieloprocesorowe - wciąż nie jest neuronalną organizacją równoległego przetwarzania informacji, która wykorzystuje ludzkie myślenie. Opracowanie algorytmu zawsze odwołuje się do jednego procesu, aczkolwiek podzielonego na wiele strumieni. Programowanie wciąż znajduje się na jednym poziomie, nawet jeśli kod jest zbudowany w formacie systemu oddziałujących obiektów, których wystąpienia działają samodzielnie. Pytanie to nie tyle struktura systemów informatycznych w postaci niezależnych obiektów, ile w otoczeniu, które zapewnia ich funkcjonowanie. Środa jest spójna, a nie równoległa. Wzrost liczby rdzeni i liczba procesorów na jednym komputerze, tablecie lub innym urządzeniu nie czyni z nich skojarzonych urządzeń komputerowych.
Ale dane wyjściowe nadal istnieją: każda konkretna aplikacja jest problemem, na który należy znaleźć szybką odpowiedź. Trzeba dokonać szybkiego wyboru (limit MySQL), pomimo faktu, że inne funkcje (MySQL ORDER BY, grupy przez, join & amp; gdzie) nie zostaną naruszone, tabela zostanie podzielona na wiele identycznych części, a pamięć podręczna procedura dostanie aktualizacji natychmiast po aktualizacji , a nie wtedy, gdy otrzymują inny "szczególny powód". Język SQL to dobry język, ale jeśli dodasz do niego skojarzenia, będzie jeszcze lepiej.