Jak wiadomo, komputer przechowuje informacje w formie binarnej, reprezentując je jako sekwencję jednostek i zer. Aby przetłumaczyć informacje na formę wygodną dla ludzkiej percepcji, każda unikalna sekwencja cyfr wyświetlana jest zastępowana przez odpowiedni znak. Jednym z systemów korelacji kodów binarnych ze znakami drukowanymi i sterującymi jest kodowanie ASCII. Na dzisiejszym poziomie rozwoju technologii komputerowej od użytkownika nie wymaga znajomości kodu każdej konkretnej postaci. Jednak ogólne zrozumienie sposobu kodowania jest niezwykle użyteczne, a dla niektórych kategorii specjalistów jest to absolutnie konieczne.
Tworzenie ASCII
Oryginalne kodowanie zostało opracowane w 1963 roku, a następnie aktualizowane przez 25 lat. W pierwotnej wersji tablica znaków ASCII zawierała 128 znaków, później pojawiła się wersja rozszerzona, w której zapisano pierwszych 128 znaków, a kody z zastosowanym 8-bitem pasują do poprzednio niezaznaczonych znaków.
Przez wiele lat kod ten był najpopularniejszy na świecie. W 2006 r. Łacina 1252 objęła prowadzenie, a od końca 2007 r. Do chwili obecnej Unicode zajmuje pozycję lidera.
Przesyłanie danych ASCII
Każdy znak ASCII ma własny kod składający się z 8 znaków, reprezentujących zero lub jednostkę. Minimalna liczba w tej reprezentacji wynosi zero (osiem zer w systemie dwójkowym), który jest kodem pierwszego elementu w tabeli.
MaksimumKod binarny w wersji domyślnej ASCII są zerowe + siedem jednostek, aw wersji rozszerzonej - osiem jednostek, połączonych za ósmy bit.
Zdjęcia sterowania
znaki sterujące nazywane znaków bez reprezentacji graficznej wykorzystywany do organizowania tekstu, zarządzania urządzeniami, i tak dalej. D. Mogą one oznaczać początek lub koniec tekstu, kart dźwiękowych, generowanie różnych operacji, dla teleksu (TTY - dane maszyny w kanale elektrycznym) urządzenie wyjściowe rozdzielczości, cofanie i inni
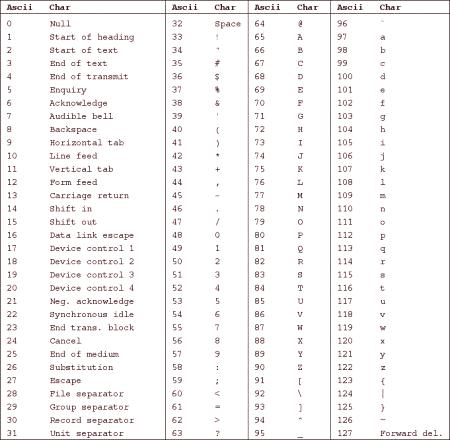
W tabeli znaków ASCII pozycje od 0 do 31 i 127 są przydzielane pod znakami kontrolnymi. Razem z 33 znaków
Inne postacie
Pozostałe 95 miejsc zarezerwowanych dla znaków interpunkcyjnych i operacji matematycznych, cyfr, liter alfabetu, innego rejestru: „A” i duże „A” kodów poziome odpowiadają różnym tablicy symboli ASCII
Pokoje znaków w tabeli
Jeżeli dana osoba jest zaangażowana w rozwój oprogramowania lub wykonania innej zadanie technologii informacyjnej, musi znać liczbę szeregu znaków ASCII. Jak wspomniano powyżej, pozycje 0-31 i 127 zajmują symbole kontrolne. Numer 32 jest zamocowana na powierzchni, numery 33-47 i 58-64 zarezerwowane dla znaków interpunkcyjnych i podstawowych operacji matematycznych.
Łacińskie litery są ułożone alfabetycznie i mają numery od 65 do 90. Rzędy są również ułożone alfabetycznie, ich pozycje - od 97 do 122. Pozostałe liczby (91-96 i 123-126) są ustalone na kwadratowych i nawiasach klamrowych,ukośne i proste, a także znaki diakrytyczne. Pełną tabelę symboli w wygodnej graficznej reprezentacji można zobaczyć na powyższym obrazku. Poniższy rysunek pokazuje liczbę znaków w rosyjskiej tabeli znaków ASCII.
Rozszerzony ASCII
Ponieważ kod źródłowy został zaprojektowany dla użytkownika amerykańskiego, nie przewidział on nie tylko różnych rodzajów pisma i alfabetów narodowych, ale nawet wygodnego używania znaków diakrytycznych aktywnie wykorzystywanych w językach europejskich.
Do generowania rozszerzonego kodowania użyto ósmego bitu. Ta wersja zawiera znaki narodowych europejskich alfabetów i transkrypcji fonetycznej, elementy grafiki używane do rysowania tabel, serię znaków matematycznych. Niektóre znaki ASCII są dziś rzadko używane. W szczególności odnosi się do znaków używanych do rysowania tabel, ponieważ przez lata od opracowania rozszerzonego kodowania wprowadzono znacznie wygodniejsze sposoby graficznej reprezentacji tabel.
Krajowe wersje kodu
Po pojawieniu się rozszerzonego wariantu ASCII do wyświetlania alfabetów narodowych zastosowano konwertowane wersje kodowania, w których zamiast znaków alfabetu łacińskiego umieszczono znaki rosyjskie, greckie i arabskie. Dwa kody w tabeli zostały ustawione na przełączanie pomiędzy standardowym US-ASCII i jego wariantem narodowym.
Po tym, jak ASCII zaczął zawierać nie 128 i 256 znaków, dystrybucja stała się opcjąkodowanie, w którym oryginalna wersja tabeli była przechowywana w pierwszych 128 kodach z zerowym 8-bitowym. Oznaki pisarstwa narodowego były przechowywane w górnej połowie tabeli (pozycja 128-255). Nie musisz znać kodów znaków ASCII bezpośrednio. Deweloper oprogramowania zazwyczaj wystarczy znać numer pozycji w tabeli, aby w razie potrzeby obliczyć jego kod za pomocą systemu binarnego.
Język rosyjski
Po opracowaniu na początku lat 70-tych kodowania języków skandynawskich, chińskiego, koreańskiego, greckiego itd., Związek Sowiecki przyjął własną wersję. Wkrótce 8-bitowy wariant kodujący KOI8 zachował pierwsze 128 kodów znaków ASCII i przydzielił te same pozycje literom alfabetu narodowego i dodatkowym znakom. Wdrożenie Unicode KOI8 zdominował rosyjski segment Internetu. Istniały warianty kodowania zarówno rosyjskiego, jak i ukraińskiego alfabetu.
Problemy z ASCII
Ponieważ liczba elementów nawet w rozwiniętej tabeli nie przekraczała 256, nie było możliwości umieszczenia w jednym kodowaniu kilku różnych skryptów. W latach 90. Runet miał problem z "krocozyabr", gdy teksty pisane przez rosyjskie znaki ASCII nie były wyświetlane poprawnie. Problem polegał na niedopasowaniu kodów różnych wariantów ASCII do siebie. Przypomnijmy, że pozycje 128-255 mogą mieć różne znaki, a przy zamianie jednego cyrylicy na inny, wszystkie litery tekstu zostały zastąpione innymi, mając identyczną liczbę w innymwersje kodowania.
Current Status
Wraz z nadejściem Unicode, popularność ASCII gwałtownie spadła. Powodem tego jest fakt, że nowe kodowanie pozwoliło na umieszczenie postaci niemal wszystkich języków pisanych. W tym przypadku pierwsze 128 znaków ASCII odpowiada tym samym znakom w kodowaniu Unicode.
W 2000 r. Kod ASCII był najpopularniejszym kodowaniem w Internecie i był używany przez 60% stron Google zaindeksowanych przez Google. W 2012 roku udział takich stron spadł do 17%, a Unicode (UTF-8) stał się najpopularniejszym źródłem kodowania. Tak więc ASCII jest ważną częścią historii technologii informatycznych, ale jej wykorzystanie w przyszłości wydaje się mało obiecujące.