Współczesny Internet opiera się na komunikacji między klientem (przeglądarką) a serwerem. Opracowano specjalne protokoły, które umożliwiają wymianę informacji między sobą. Jednym z nich jest HTTP, dzięki któremu użytkownicy mogą pracować za pośrednictwem przeglądarki i przeglądać strony HTML.
Co to są nagłówki HTTP
HTTP to sposób na wymianę stron HTML między dwoma komputerami. Protokół został wynaleziony w 1990 roku i jest obecnie główną metodą wyświetlania stron hipertekstowych.
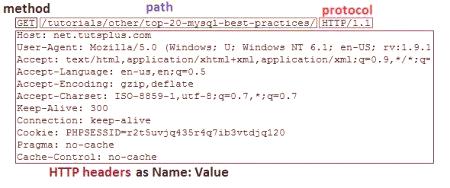
Nagłówki HTTP to linie, z którymi komunikują się komputery. Przypomina dialog pomiędzy ludźmi. Przeglądarka po otwarciu witryny generuje żądanie, dostarcza niezbędnych informacji o sobie (język, kraj, link do zasobu, wersja jądra itp.). Wszystkie te informacje są wysyłane na serwer i istnieje pewien program (Apache, Nginx, LiteSpeed itp.). Czyta otrzymane linie i, w zależności od pytania, generuje odpowiedź. Na przykład mężczyzna postanowił otworzyć witrynę google.com, wpisuje link w polu wyszukiwania, a przeglądarka generuje żądanie. Nagłówek HTTP przeglądarki wygląda następująco:
Linia początkowa
Pokaż google.com
Zapytanie
)
Jestem z Rosji Używam przeglądarki Google Chrome Potrzebuję kodu HTML Mam informacje użytkownika
Treść HTTP
Expect
Serwer przetwarza dane i generuje odpowiedź:
Linia początkowa
Wszystko jest dobrze, strona została znaleziona i działa
Odpowiedź
Pracuję nad ApacheStrona zmieniona na 27052017 Kodowanie UTF-8
Treść wiadomości
Uzyskaj kod strony Jest to nowa informacja od użytkownika (login, hasło)
Treść wiadomości przesyła kod HTML strony.
Funkcje protokołu HTTPS
Obecnie większość witryn migruje z połączenia HTTP i HTTPS. Różnica między nimi polega na dodatkowym szyfrowaniu wszystkich przesłanych informacji. Przed rozpoczęciem wymiany klient wymaga certyfikatu SSL w celu zweryfikowania autentyczności serwera. Dla programisty nic się nie zmienia i może on dalej pracować bez zmiany swojego kodu.
Po otrzymaniu certyfikatu klient sprawdza autentyczność (certyfikat jest porównywany z serwerem i porównywany jest certyfikat z centrum). Jeśli wszystko jest w porządku, uruchamia się protokół HTTP. Po potwierdzeniu nagłówki certyfikatu są szyfrowane za pomocą RSA. Osoba atakująca nie może ukraść ważnych informacji o użytkowniku (login, hasło itp.).
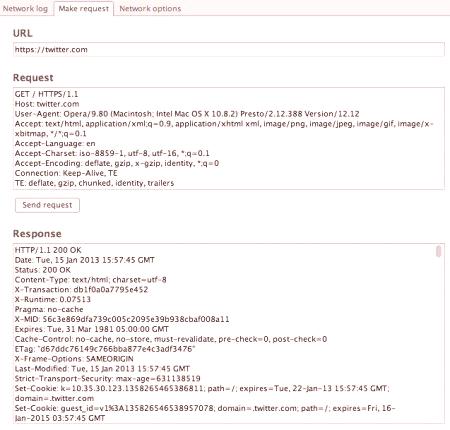
Wyświetlanie okna dialogowego HTTP
Możesz samemu wyświetlić okno dialogowe HTTP. Zwroty używają specjalnych skrótów - Date, Cookie, Host, Server itp. Nagłówki HTTP View-mogą być używane z rozszerzeniami przeglądarki. Pomóż także w tej usłudze online. Aby wyświetlić nagłówki HTTP z wtyczek, użyj:
Firebug.
Live HTTP Headers.
nagłówki HTTP.
Z usług online skorzystaj:
Bertal.ru.
stupid.su.
Speed-Tester.Info.
Przechwytują nagłówki odebrane z serwera i wyświetlają je w osobnym oknie. Z jednej strony można uzyskać od razu 100-200 nagłówków i mogą one okresowowyruszyć po chwili. Na przykład, aby sprawdzić online w sieciach społecznościowych. Nagłówki HTTP można podzielić na cztery typy:
ogólne (nagłówki ogólne) - zastosowanie w zapytaniu i odpowiedziach;
dla zapytania (nagłówki zapytań) - na żądanie;
w przypadku odpowiedzi (nagłówki odpowiedzi) - w przypadku odpowiedzi;
Nagłówki encji - zapytania i odpowiedzi.
Linia początkowa od klienta
Aby rozpocząć wymianę informacji, najpierw tworzona jest główna linia. Klient w nim mówi, jakiego pliku lub obiektu potrzebuje. Aby to zrobić, istnieją pewne sposoby uzyskania dostępu do protokołu. Struktura linii początkowej składa się z trzech części:
Metoda wniosku
Obiekt
protokół
POST
/c840024/upload.php
HTTP /1.1
po to koniecznie następuje po linii Host i określa adres URL witryny. Istnieją różne metody zapytań. Programiści najczęściej używają:
GET - żądanie informacji (odpowiedź jest wysyłana przez serwer w łączu).
POST - wysyłanie informacji do serwera w sposób ukryty (odpowiedź nie jest widoczna na pasku adresu).
HEAD jest taki sam jak GET, ale serwer zwraca tylko nagłówek.
PUT - wysyłanie dużych żądań URL;
Po wysłaniu linii startowej znajdują się wszystkie inne nagłówki - User Agent, Cookie itp. Bez głównego żądania nie można rozpocząć wymiany informacji przez HTTP. Nagłówki są jedynie dodatkiem w protokole 1.0 i mogą w ogóle nie być transmitowane.
Przekazywanie informacji od klienta
Po przeniesieniu początkowej linii klientawysyła twoje dane do hostingu, na przykład wersję przeglądarki i używany język. W razie potrzeby serwer może dodatkowo zażądać od klienta i innych informacji:
Obowiązkowe (zawsze wysyłane) nagłówki żądania HTTP to Host, Referer, User Agent i Accept. Programista nie może wpływać na nagłówki żądań, są one tworzone przez przeglądarkę. Możesz skonfigurować ich transfer w samym programie za pomocą dodatkowych rozszerzeń.
Nagłówki HTTP serwera - odpowiedź na żądania stron
Po otrzymaniu żądań od klienta strona przekazuje określone wiersze serwera. Funkcja header () jest używana w php do przesyłania nagłówka HTTP- . Na przykład możesz zgłosić nową lokalizację strony: nagłówek ("Lokalizacja: http://www.site.com/"). Ze strony na serwerze dane są wysyłane do klienta wraz z niezbędnymi informacjami. Ta metoda pozwala poznać wymagane informacje z serwera:
Głównie, te zapytania są potrzebne, aby poprawnie wyświetlić stronę w przeglądarce. Służą do zwiększenia prędkości ładowania strony.
Essentials
Istnieją nagłówki, które rozumieją zapytanie i odpowiedź, każde żądanie jest powiązane z określonym podmiotem (strona z kodem HTML). Dzięki tym żądaniom przeglądarka przetwarza informacje o stronie. Są aktywnie wykorzystywane w buforowaniu.
Najpopularniejszym nagłówkiem jest Last-Modified. Żądanie to można wysłać z przeglądarki na serwer i odwrotnie. Poprzez ten nagłówek klient będzie wiedział, czy musi zaktualizować swoją pamięć podręczną. Przykład dialogu: Klient: "Mam pamięć podręcznąod 16052016 zmienił stronę na serwerze „Server:”.. Tak, pamięć podręczna zmieniły 19032017 Oto nowa wersja „
Serwer
Po otrzymaniu linię startu serwera klient generuje odpowiedź
HTTP
w wersji minut
stanu Tytuł
, opisu
HTTP
1,1
200
, OK
Jeśli status " związek potwierdzone, serwer może zapewnić klientom niezbędnych informacji. Przykład HTTP dialog widać poniżej,
Zapytania tworzą programista na stronie za pomocą funkcji header ().
Kody statusu
Aby kontynuować komunikację z klientem, musisz się upewnić, że serwer działa poprawnie i wyświetla się poprawnie. Aby się upewnić, odpowiedzi zostały wymyślone. Reprezentują trzycyfrową liczbę. Można przesyłać status początkowej nagłówku strony, takie jak nagłówek («http /11200 Ok»).
, strony buforowanego
Aby przyspieszyć wymianę stronach wynaleziono buforowania. Strona jest przechowywana w formie skompresowanej w pamięci komputera lokalnego. Teraz nagłówki nie muszą wysyłać dużych plików za każdym razem. Konieczne jest jedynie upewnienie się, że informacje dotyczące hostingu i klienta są takie same. Tworzone są niestandardowe żądania pamięci podręcznej, klient hostingowy po otrzymaniu nagłówków od klienta sprawdza, czy ma pamięć podręczną strony. Jeśli tak nie jest, pyta serwer. W przyszłości przed przejściem do przeglądarki w protokole będą sprawdzane tylko,Czy pamięć podręczna została zmieniona na serwerze. Aby sprawdzić informacje o kompresji dla istotności, jest określona w dacie wygaśnięcia nagłówka HTTP. Klient wysyła informacje o tym, które pliki są przechowywane lokalnie, a serwer określa jego wersję. Jeśli pasują, przeglądarka po prostu wyświetla swoją wersję pamięci podręcznej. Aby uzyskać optymalizację SEO, musisz podać datę w nagłówkach HTTP. Do tych celów używana jest Last-Modified. Ponadto pamięć podręczną można aktualizować po pewnym czasie przechowywania. Wygasa w tym celu. Cache-Control służy do konfigurowania buforowania, ponieważ pozwala na zezwolenie lub zapobieganie przechowywaniu informacji ze strony. Prawidłowe ustawienie buforowania pozwala szybko uaktualnić zasoby do najwyższych wydań dla wyszukiwarek. Algorytmy Yandex i Google okresowo odwiedzają strony witryny i przechowują pamięć podręczną w swoich archiwach. Po chwili zwracają się do serwera, aby sprawdzić trafność informacji. Jeśli informacje zostały zmienione, pliki są aktualizowane na serwerze wyszukiwarki, a uzyskane dane są ponownie indeksowane. Niektórym zaleca się przeniesienie aktualnej daty do nagłówka Last-Modified, mając nadzieję, że robot będzie na stałe przechowywać swój artykuł na górze wyszukiwania. Ale okazuje się, że algorytm musi za każdym razem zmienić informacje o pamięci podręcznej w sobie i ponownie ją zindeksować. Nie zawsze prowadzi to do dobrych wyników, a czasem może tylko pogorszyć pozycję artykułu.
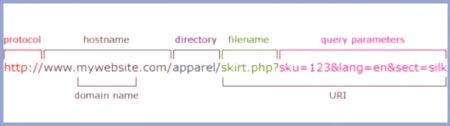
O linku URL w linii przeglądarki
Aby komunikować się z użytkownikiem hostingowym, za każdym razem wstawia link URL wpasek adresu przeglądarki. Ten zestaw symboli ma określoną strukturę, przez którą przekazywane są niezbędne informacje. Struktura łącza składa się z pięciu części:
protokół;
Interesujący obiekt i jego adres;
port do obiegu;
wiersze HTTP (wysłane przy użyciu metody GET);
kod zapytania.
Odsyłacze są dostępne nie tylko na stronach takich jak HTTP, PHP itp. Za ich pośrednictwem można przeszukiwać bazy danych lub wysyłać informacje do innego komputera. Ta metoda często hakerzy spędzają SQL injection i różne metody kradzieży informacji z baz danych witryny.
Wadą tego adresu URL jest brak wsparcia dla innych alfabetów - w większości używa się łaciny. Z tego powodu przed opublikowaniem należy dokładnie przemyśleć skrócony tytuł artykułu. W końcu wyszukiwarka na łączu ocenia przydatność zasobu i informacji, które mogą dostarczyć stronę użytkownikowi. Dlatego przy optymalizacji SEO należy zwrócić szczególną uwagę na tworzenie poprawnych adresów URL artykułów.