Sztuczna inteligencja i sieci neuronowe to niezwykle ekscytujące i potężne metody oparte na uczeniu maszynowym, które są wykorzystywane do rozwiązywania wielu rzeczywistych problemów. Najprostszym przykładem sieci neuronowej jest nauka interpunkcji i gramatyki, która automatycznie tworzy całkowicie nowy tekst z zastosowaniem wszystkich reguł pisowni.
Historia sieci neuronowej
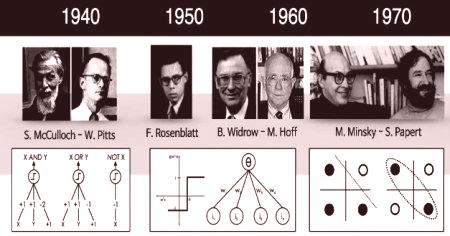
Naukowcy zajmujący się komputeryzacją od dawna próbują symulować ludzki mózg. W 1943 Warren S. McCullough i Walter Pitts opracowali pierwszy konceptualny model sztucznej sieci neuronowej. W artykule "Logiczna liczba pomysłów związanych z aktywnością nerwową" opisano przykład sieci neuronowej, pojęcie neuronu - pojedynczej komórki żyjącej w sieci ogólnej, odbierającej dane wejściowe, przetwarzającej je i generującej sygnały wyjściowe.
Ich praca, podobnie jak wielu innych naukowców, nie miała na celu dokładnego opisania pracy mózgu biologicznego. Sztuczną sieć neuronową opracowano jako model obliczeniowy, który działa na zasadzie funkcji mózgu w celu rozwiązania szerokiego zakresu zadań. Oczywiście istnieją ćwiczenia, które są łatwe do rozwiązania dla komputera, ale trudne dla osoby, na przykład, wyodrębniając pierwiastek kwadratowy z dziesięciocyfrowej liczby. Ten przykład obliczy sieć neuronową w czasie krótszym niż milisekunda, a osoba potrzebuje minut. Z drugiej strony są takie, które są niewiarygodnie łatwe do rozwiązania, ale nie na mocy komputera, na przykład, aby wybrać obraz tła.
Naukowcy spędzili dużo czasu na odkrywaniu i wdrażaniu złożonych rozwiązań. Najczęstszym przykładem sieci neuronowej w obliczeniach komputerowych jest rozpoznawanie wzorców. Zakres jest różny, od optycznego rozpoznawania znaków i drukowania zdjęć, od odręcznych skanów po cyfrowe rozpoznawanie twarzy.
Kalkulatory biologiczne
Ludzki mózg jest niezwykle złożony i najpotężniejszy ze znanych komputerów. Jego wewnętrzna praca jest wzorowana na koncepcji neuronów i ich sieci, zwanych biologicznymi sieciami neuronowymi. Mózg zawiera około 100 miliardów neuronów, które są połączone przez te sieci. Na wysokim poziomie współdziałają ze sobą poprzez interfejs składający się z końcówek aksonów powiązanych z dendrytami poprzez synapsę przestrzenną. Mówiąc prostym językiem, jeden przekazuje wiadomość do drugiego za pośrednictwem tego interfejsu, jeśli suma ważonych danych wejściowych z jednego lub więcej neuronów przekracza próg wyzwalający transmisję. Nazywa się to aktywacją, gdy próg jest przekroczony, a wiadomość jest przekazywana do następnego neuronu. Proces sumowania może być złożony matematycznie. Sygnał wejściowy jest ważoną kombinacją tych sygnałów, a ważenie każdego z nich oznacza, że to wejście może mieć różny wpływ na kolejne obliczenia i na końcowe wyjście sieci.
Elementy modelu neuronowego
Głębokie uczenie się jest terminem używanym dla złożonych sieci neuronowych składających się z kilku warstw. Warstwy składają się z węzłów. Węzeł to tylko miejsce, w którymistnieją obliczenia, które sprawdzają się w przypadku wystarczających zachęt. Węzeł integruje dane wejściowe z zestawu współczynników lub wag, które wzmacniają lub osłabiają ten sygnał, określając w ten sposób znaczenie dla zadania. Sieci z głębokim uczeniem się różnią się od wspólnego układu nerwowego jedną, ukrytą warstwą. Przykład treningu sieci neuronowych - sieć Kohonena.
W sieciach z głęboką nauką, każda warstwa rozpoznaje dany zestaw funkcji w oparciu o oryginalne informacje z poprzedniego poziomu. Dalszy ruch do sieci neuronowej, trudniejsze obiekty, które mogą być rozpoznane przez węzły, ponieważ łączą i rekombinują obiekty z poprzedniego poziomu. Sieci głębokiego uczenia się wykonują automatyczne pobieranie funkcji bez interwencji człowieka, w przeciwieństwie do większości tradycyjnych algorytmów i kończą się poziomem początkowym: klasyfikator logiczny lub softmax, który przypisuje prawdopodobieństwo określonego wyniku i jest nazywany rokowaniem.
Black Box ANN
Sztuczne sieci neuronowe (SNN) są modelami statystycznymi częściowo modelowanymi na podstawie biologicznych sieci neuronowych. Są w stanie poradzić sobie z nieliniową relacją między wejściami i wyjściami równolegle. Takie modele charakteryzują się obecnością obciążeń adaptacyjnych wzdłuż ścieżek między neuronami, które mogą być konfigurowane przez algorytm uczenia w celu poprawy całego modelu.
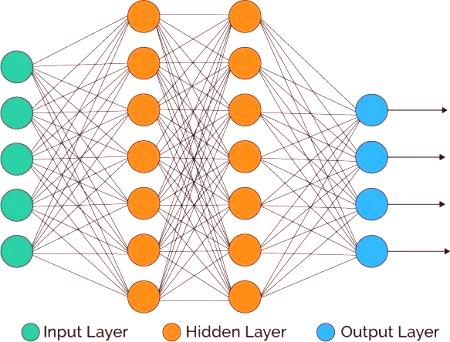
Prostym przykładem sieci neuronowej jest architektonicznie sztuczna sieć neuronowa ANN, w której:
Warstwa wejściowa jest warstwą wejściową.
Ukryta warstwa to ukryta warstwa.
Warstwa wyjściowa - Warstwa wyjściowa.
jest modelowany za pomocą warstw sztucznych neuronów lub jednostek obliczeniowych, które mogą odbierać napływające dane i wykorzystują aktywacyjny progową w celu stwierdzenia, czy wiadomość jest transmitowana. W prostym modelu pierwszej warstwie - to wejście, a następnie przez ukrytą i końcu produkcji. Każdy może zawierać jeden lub więcej neuronów. Modele mogą stać się bardziej skomplikowana ze zwiększonymi możliwościami abstrakcji i rozwiązywanie problemów, liczba warstw ukrytych, liczbę neuronów obecnych w każdej warstwie i liczby ścieżek między nimi. Architektury i konfiguracji modele są główne elementy metody Ann oprócz większości algorytmów uczenia. Są niezwykle wydajne i są uważane algorytmy czarne skrzynki, co oznacza, że ich wewnętrzna pracuje bardzo ciężko, aby zrozumieć i wyjaśnić.
algorytmy głębokie nauki
Głęboko learning - koncepcja brzmi dość głośno, właściwie to termin, który opisuje niektóre rodzaje sieci neuronowych i algorytmów stowarzyszonych zużywają surowych danych wejściowych przez wiele warstw nieliniowych transformacji do obliczania docelowy wynik Nieatrakcyjna cecha jest również obszarem, w którym głębokie wykształcenie przekracza wszelkie oczekiwania. Przykład nauczania sieci neuronowych - sieci SKIL.
Tradycyjnie naukowiec lub programista danych jest odpowiedzialny za przeprowadzenie procesu wyodrębniania atrybutów w większości innych podejść do uczenia maszynowego wraz z wyborem funkcji i projektu.
Optymalne parametry algorytmu
Algorytmyfunkcje uczenia upoważniają maszynę do uczenia się określonego zadania przy użyciu ograniczonego zestawu możliwości uczenia się. Innymi słowy, uczą się uczyć. Zasada ta jest z powodzeniem stosowana w wielu aplikacjach i jest uważana za jedną z zaawansowanych metod sztucznej inteligencji. Odpowiednie algorytmy są często używane do kontrolowanych, niekontrolowanych i częściowo kontrolowanych zadań. W modelach opartych na sieci neuronowej liczba warstw jest większa niż w algorytmach treningu powierzchniowego. Małe algorytmy są mniej złożone i wymagają głębszej wiedzy o optymalnych funkcjach, które obejmują selekcję i rozwój. Wręcz przeciwnie, algorytmy głębokiego uczenia się polegają bardziej na optymalnym wyborze modelu i jego optymalizacji poprzez dostosowanie. Są lepiej przystosowane do rozwiązywania problemów, gdy wcześniejsza znajomość funkcji jest mniej pożądana lub konieczna, a utrwalone dane są niedostępne lub nie są niezbędne do użycia. Dane wejściowe są przekształcane na wszystkie warstwy przy użyciu sztucznych neuronów lub bloków procesorów. Przykład kodu sieci neuronowej nazywa się CAP.
Wartość CAP
WPR jest wykorzystywana do pomiaru architektury modelu głębokiego uczenia się. Większość badaczy w tej dziedzinie zgadza się, że ma ona więcej niż dwie nielinearne warstwy WPR, podczas gdy niektórzy uważają, że WPR, mająca więcej niż dziesięć warstw, wymaga zbyt wielu szkoleń.
Szczegółowe omówienie wielu różnych architektur modeli i algorytmów tego rodzaju szkoleń jest bardzo przestrzenne i kontrowersyjne. Najbardziej przebadani to:
Directsieci neuronowe.
Nawracająca sieć neuronowa.
Wielowarstwowy Perceptron (MLP).
Rolling Neural Networks.
Rekurencyjne sieci neuronowe.
Głębokie sieci przekonań.
Rusztowanie głębokich wyroków skazujących.
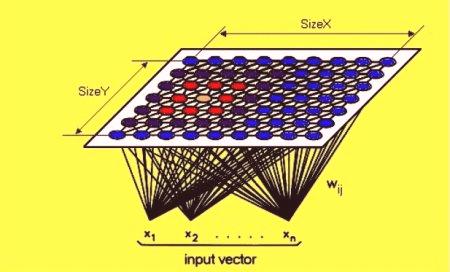
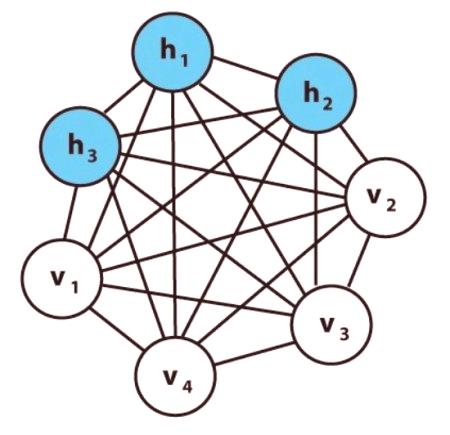
Mapy samoorganizujące się.
Głębokie samochody Boltzmanna.
Złożone auto-sensory emitujące hałas.
Najlepsze współczesne architektury
Perceptrony są uważane za sieci neuronowe pierwszej generacji, modele obliczeniowe jednego neuronu. Zostały one wynalezione w 1956 roku przez Franka Rosenblatta w "Perceptron: Przewidywany model przechowywania i organizacji informacji w mózgu". Perceptron, zwany także siecią bezpośrednich połączeń, przesyła informacje z przodu do tyłu. Rekurencyjne sieci neuronowe RNN przekształca sekwencję wejściową na wyjście, które znajduje się w innym obszarze, na przykład zmienia kolejność ciśnień dźwięku w sekwencję identyfikatorów słów. John Hopfield przedstawił Hopfield Net w artykule z 1982 r. "Sieci neuronowe i systemy fizyczne z rozwijającymi się zbiorowymi możliwościami obliczeniowymi". W sieci Hopfielda (HN) każdy neuron jest połączony z każdym innym. Uczą się, ustawiając ich wartość na pożądany schemat, po czym możemy obliczyć współczynniki wagowe.
Maszyna Boltzmanna jest rodzajem stochastycznej powtarzalnej sieci neuronowej, którą można uznać za analogię sieci Hopfielda. Był to jeden z pierwszych wariantów badania wewnętrznych reprezentacji, które rozwiązują złożone problemy kombinatoryczne.Przychodzące neurony stają się danymi wyjściowymi na końcu pełnej aktualizacji. Generic Competitive Network, Jan Goodfellow (GAN), składa się z dwóch sieci. Często połączeniem Forward paszowym i splotowego Neural Nets. Generalnie generuje się zawartość, a druga powinna oceniać treści dyskryminujące.
SKIL Wprowadzenie Pythonie
głęboko szkolenia sieci neuronowej według przykładu Pythona porównuje wejść i wyjść korelacji. Znany jest jako uniwersalny approksymator ponieważ może nauczyć się podchodzić nieznanej funkcji f (x) = Y pomiędzy dowolnym wejściem «x» i każdym wydaniu «y», co sugeruje, że są one związane z korelacją lub przyczynowego BC „yazkom. W nauce prawidłowego «f» lub sposób przekonwertować «x», «y», czy f (x) = 3x + 12 lub f (x) = 9x - 01. Zadaniem klasyfikacji zestawów danych dotyczących sieci neuronowych przeprowadziła korelację między etykietami i danymi. Znane kontrolowane szkolenie następujących typów:
rozpoznawanie osób;
Identyfikacja osób na obrazach;
określenie wyrazu twarzy: zły, radosny;
identyfikacji obiektów w obrazie, stop znaki, piesi, znaki pasów ruchu;
rozpoznawanie gestów w wideo;
określanie głosu mówców;
klasyfikacja tekstu spamu.
Przykład svertochnoy sieci neuronowe
Svertochnaya sieć neuronowa jak sieć wielowarstwowa perceptronu. Główną różnicą jest to, że CNN bada, jak jest skonstruowany iw jakim celu jest używany. Inspiracją dla CNN były procesy biologiczne. Ich struktura ma wygląd kory wzrokowej występującej u zwierzęcia.Są stosowane w dziedzinie wizji komputerowej i udanych osiągnięć nowoczesnych poziomów wydajności w różnych dziedzinach badań. Zanim zaczną kodować CNN, do budowy modelu używana jest biblioteka, na przykład Keras z backendem Tensorflow. Najpierw dokonaj koniecznego importu. Biblioteka pomaga zbudować splotową sieć neuronową. Pobierz zestaw danych mnist za pośrednictwem Keras. Zaimportuj model seryjnej keras, który może dodawać warstwy pętli i scalania, gęstych warstw, ponieważ są one używane do przewidywania etykiet. Warstwa opuszczająca redukuje ponowne wyposażenie, a poziomowanie przekształca wektor trójwymiarowy w jednowymiarowy. Na koniec, importuj numpy dla operacji macierzowych:
Y = 2 # wartość 2 oznacza, że obraz ma cyfrę 2;
Y = [0,0, 1, 0,0,0,0,0,0,0,0] # trzecie miejsce w wektorze to 1;
# Tutaj wartość klasy jest przekształcana na binarną macierz klas.
Algorytm konstrukcyjny:
Dodaj do modelu sekwencyjnego dokładne warstwy maksymalnej puli.
Dodaj między nimi warstwy upuszczania. Rozwijany ekran losowo odłącza niektóre neurony w sieci, co zmusza dane do znalezienia nowych ścieżek i zmniejsza ponowne wyposażenie.
Dodaj ciasne warstwy, które są używane do przewidywania klasy (0-9).
Skompiluj model z kategoryczną funkcją utraty entropii krzyżowej, optymalizatorem Adadelta i miarą dokładności.
Po treningu oszacuj stratę i dokładność modelu zgodnie z danymi testu i wydrukuj.
Modelowanie w Matlabie
Oto prosty przykład neutralnych sieci modelowania Matlaba. Zakładającże „a”, model ten ma trzy wejścia „a”, „b” i „c”, i generuje sygnał wyjściowy „Y”.
Do celów generowania danych: = 5a + bc + 7s. Najpierw napisz mały skrypt do wygenerowania danych:
a = Rand (11000);
b = plaża (11000);
z Rand (11000);
n = Rand (11000) * 005;
,
y = a * b + 5 + 7 * S * S + n,
, w którym n - hałas dodawany jest, aby wyglądać jak rzeczywistych danych. Wartość szumu wynosi 01 i jest jednolita. Tak więc, wejście - zestaw "a", "b" i "c" i stwierdzono,
i = [A; b; c];
O = y.
Następnie użyj wbudowanej funkcji matlab newff do wygenerowania modelu.
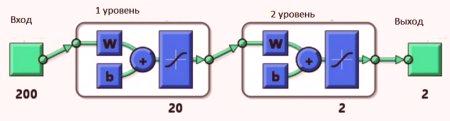
Przykłady sieci neuronowych
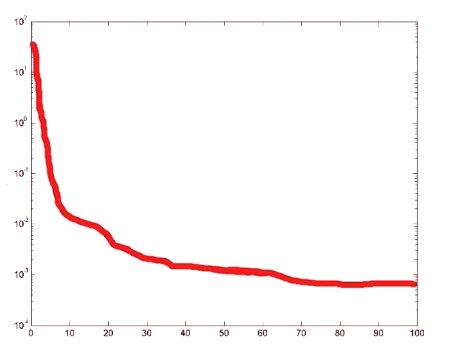
Po pierwsze, tworząc matrycę 3 * r 2. Pierwsza kolumna pokazuje minimum trzech wejść, a drugi - do maksymalnie trzech wejść. W tym przypadku trzy wejścia mieszczą się w zakresie od 0 do 1 dla: R = [0 1; 0 1; 0 1]. Teraz utwórz macierz wielkości, która ma rozmiar v wszystkich warstw: S = . Obecnie nazywa newff następująco: netto = newff ([0 1, 0 1, 0 1], S { 'tansig', 'purelin'}). Neuronowy model {'tansig', 'purelin'} pokazuje funkcję wyświetlania dwóch warstw. Naucz go danymi, które zostały utworzone wcześniej: net = train (net, I, O). Sieć jest wyszkolona, można zobaczyć krzywą wydajności, jak się uczy.
Teraz ponownie modelowania go na tych samych danych i porównania oryginalne dane: O1 = SIM (netto I); wykres (1: 1000O, 1: 1000Ol). Tak więc, matryca wkład będzie:
net.IW {1}
-05 402 -036840,0308
+046400,234005875
19 569 -168871,5403
+111381,084102439
net.LW {21}
-10006 -09138 -1119909,4589
Programy sztucznej inteligencji
Przykłady realizacji sieci neuronowych to rozwiązanie samoobsługowe online do tworzenia iniezawodne przepływy pracy. Istnieją modele głębokiego uczenia się używane w czatach, ponieważ nadal ewoluują, można się spodziewać, że obszar ten będzie częściej wykorzystywany przez wiele różnych przedsiębiorstw. Obszary zastosowań:
Automatyczne tłumaczenie maszynowe. To nie jest coś nowego, głębokie uczenie się pomaga poprawić automatyczne tłumaczenie tekstu za pomocą złożonych sieci i pozwala przetłumaczyć obraz.
Prosty przykład korzystania z sieci neuronowych - dodawanie kolorów do czarno-białych zdjęć i filmów. Można to zrobić automatycznie, korzystając z dogłębnych modeli badań.
Maszyny uczą się interpunkcji, gramatyki i stylu tekstu i mogą używać opracowanego przez siebie modelu do automatycznego tworzenia zupełnie nowego tekstu z właściwą pisownią, gramatyką i stylem tekstu.
ANN sztuczne sieci neuronowe i bardziej wyrafinowane techniki głębokiego uczenia się to jedne z najbardziej zaawansowanych narzędzi do rozwiązywania skomplikowanych zadań. Chociaż zastosowanie boomu jest mało prawdopodobne w najbliższej przyszłości, postęp technologii i zastosowań sztucznej inteligencji z pewnością będzie fascynujący. Pomimo tego, że rozumowanie dedukcyjne, wnioski logiczne i podejmowanie decyzji przy pomocy komputera są dziś dalekie od doskonałości, poczyniono znaczne postępy w stosowaniu metod sztucznej inteligencji i powiązanych algorytmów.