Zaawansowane funkcje programu Excel zapewniają niezastąpione i wygodne metody do różnych obliczeń statystycznych i analiz. Jedną z takich cech jest przedział ufności stosowany do wyrażenia stopnia niepewności związanej z badaniami. Przedziały ufności w programie Excel to ocena zdarzeń połączona z weryfikacją prawdopodobieństwa. Zapewniają prawdopodobny zakres proporcji próbek lub średnią selektywną rzeczywistego udziału /średniej w populacji i wyświetlają się jako: wynik +/- błąd.
Funkcja interwału zaufania
W każdym badaniu i badaniach przedziały ufności są doskonałym sposobem na zrozumienie roli błędów przykładowych w średnich wartościach procentowych. W przypadku każdego badania, ponieważ badacze zawsze badają jedynie proporcje większego obliczenia, ich oszacowania są niepewne, co będzie błędem próbki.
Przedział ufności (CI) daje wyobrażenie o tym, jak bardzo średnia wartość może się zmieniać. Reprezentuje zakres wartości, które są równo wyśrodkowane na znanej średniej wielkości próbki. Im wyższy poziom ufności (w procentach), tym mniejszy przedział czasu, tym dokładniejsze wyniki. Badanie próbek o większej zmienności lub dużych odchyleniach standardowych generuje szersze przedziały ufności w programie Excel. Istnieje stosunek odwrotności pierwiastka kwadratowego między DI a wielkością próbki. Mniejsze rozmiary generują szersze elementy CI, aby uzyskać większą dokładnośćszacuje lub zmniejsza połowę błędu krańcowego, konieczne jest czterokrotne zwiększenie wielkości próby.
Budowa średnia łączna
Aby zbudować przedział ufności dla średniej kruszywa, pod warunkiem wielkości próby prawdopodobieństwo, trzeba użyć funkcji „Zaufanie” w programie Excel, który wykorzystuje rozkładu normalnego do obliczenia wartości zaufanie Na przykład badacze losowo wybrali 100 osób, zmierzyli ich wagę i ustawili średnio 76 kg. Jeśli znasz średnią dla ludzi z danego miasta, że jest mało prawdopodobne, że to do większej grupy będą miały taką samą wartość średnią jako próbki składającej się z zaledwie 100 osób. Znacznie bardziej prawdopodobne, że średnia próbka 76 kg może być w przybliżeniu równa (unknown) populyatsyonnomu średnie i trzeba wiedzieć, jak dokładny jest szacowana odpowiedź. Ta niepewność związana z oszacowaniem przedziałów, zwana poziomem niezawodności, zwykle wynosi 95%. UFNOŚĆ funkcja „(alfa, Sigma, n) zwraca wartość, która jest używana do budowy MDI średnią liczbę populacji. Przewiduje się, że te próbki spełniają standardowe rozkładu normalnego, przy odchyleniu standardowym znanym sigma, a wielkość próbki wynosi n. Przed obliczony przedział ufności Excel poziomu 95%, z tym, że alfa 1 - 095 = 005
formatów funkcja uFNOŚĆ
Zastosowanie pewności albo kredyt, granice ufności określona. - dolna i górna granica CI stopa 95% na przykład, w badaniach doskonałości Stwierdzono, że 70% ludzi w leżeć Borjomiw porównaniu do Pepsi z CI 3% i poziomem ufności 95%, wówczas istnieje 95% prawdopodobieństwo, że prawdziwa proporcja wynosi od 67 do 73%. Funkcje "CONFIDENCE" są wyświetlane pod różnymi składniami w różnych wersjach Excela. Na przykład program Excel 2010 ma dwie funkcje: "ZAUFANIE. NORMY I ZAUFANIE T", które pomagają obliczyć szerokość "CI. ZAUFANIE. NORM" jest używane, gdy znane jest standardowe odchylenie pomiaru. W przeciwnym razie użyj "TRUST.T", ocena opiera się na danych z próbki. Przedziały ufności w programie Excel do 2010 r. Miały tylko funkcję "ZAUFANIA". Jego argumenty i wyniki były podobne do argumentów funkcji "TRUST .NORM". Pierwszy jest dostępny w późniejszych wersjach programu Excel w celu zapewnienia zgodności. #NUM! Błąd występuje, jeśli wartość alfa jest mniejsza lub równa 0 lub większa lub równa 0. To odchylenie standardowe jest mniejsze lub równe 0. Podany rozmiar argumentu jest mniejszy niż jeden. # VALUE! Błąd występuje, jeśli któryś z podanych argumentów nie jest liczbą.
Funkcja interpolacyjna zaufania
"ZAUFANIE". jest klasyfikowany według funkcji statystyki i oblicza i zwraca wartość CI dla średniej. Sprawdzone przedziały czasu mogą być niezwykle przydatne do analizy finansowej. Jako analityk "ZAUFANIE". Pomaga w prognozowaniu i dostosowywaniu do szerokiego zakresu celów poprzez optymalizację decyzji finansowych. Odbywa się to za pomocą graficznej reprezentacji danych w zestawie zmiennych. Analitycy mogą podejmować bardziej skuteczne decyzje na podstawie informacji statystycznych dostarczanych przez normalnychdystrybucja. Na przykład mogą znaleźć związek między dochodami i wydatkami, które wydają na przedmioty luksusowe. Aby obliczyć średnią wartość agregacji dla elementu CI, który zwraca wartość zaufania, należy go dodać ze średniej próbki. Na przykład dla średniego rozmiaru próbki x: przedział zaufania = x ± TRUST. Przykład obliczenia przedziału ufności w programie Excel - załóżmy, że mamy następujące dane:
Znaczenie: 005.
Odchylenie standardowe populacji: 25.
Wielkość próbki: 100.
Funkcja Interwał zaufania Excel jest używany do obliczenia wartości DI o wartości 005 (to znaczy poziomu autentyczności 95%) dla średniego czasu próbkowania w celu zbadania czasów przełączania w biurze dla 100 osób. Średnia wielkość próbki wynosi 30 minut, a odchylenie standardowe wynosi 25 minut. Przedział ufności wynosi 30 ± 048999, co odpowiada zakresowi 29510009 i 3048999 (minut).
Przedziały i rozkład normalny
Najbardziej znanym zastosowaniem przedziału ufności jest "błąd błędu". W ankietach błąd wynosi plus minus 3%. DI są przydatne w kontekstach wykraczających poza tę prostą sytuację. Mogą być używane z nienormalnymi dystrybucjami, które są wysoce zniekształcone. Aby obliczyć prognozę przedziału ufności w programie Excel, wymagane są następujące bloki konstrukcyjne:
Średnia.
Standardowe odchylenie obserwacji.
Liczba ankiet w próbie.
Poziom zaufania, który należy zastosować do IK.
Przed zbudowaniem przedziału ufności w Excelu uczą sięwokół jej średniej próbki, zacznij decydując się przyjąć częstotliwość próbkowania innych środków, jeśli były one gromadzone i obliczane w tym zakresie. W takim przypadku, 95% możliwych próbki są wychwytywane Cl 196 odchylenia standardowe powyżej i poniżej próbki.
średni błąd standardowy
Dopuszczalny zakres błędu lub nie podejmuje się na podstawie pomiaru błędu lub odchylenia jako rzeczywistą niepewność może być wyższe niż wskazane. Przed obliczania przedziałów ufności do programu Excel, obliczenia należy zapewnić dobrą zbierania danych, solidnej konstrukcji systemów pomiarowych i zadowalającej kontroli. przedziały ufności dla średniej można uzyskać na kilka sposobów: poprzez SigmaXL, statystyki opisowej, histogramy, 1-shaped interwały t-test i ufności, jednokierunkowa ANOVA i schematy Multi-Vari. Graficznie zilustrować CI dla średniej „Satysfakcja” stworzyć schemat Wielu Vari (95% CI opcje Mean) używając Data.xls dane klienta. Punkty odpowiadają oddzielnym danym. Znaczniki pokazują maksymalny poziom ufności 99% i średni limit 95%. Teraz będą wykorzystywane hipotezy testowania w celu zapewnienia bardziej dokładnych średnich ocen satysfakcji i określenia statystycznej istotności wyników.
Obliczenia za pomocą SigmaXL
Przedziały ufności są bardzo ważne dla zrozumienia i podejmowania decyzji w ich sprawie. Aby obliczyć wartości CI dla dyskretnej proporcji, użyj SigmaXL & gt; Szablony i kalkulatory & gt; Podstawowyszablony statystyczne & gt; 1 interwał relacji zaufania. Zanim znajdziesz przedziałem ufności Excel, należy wykonać następujące czynności:
Otwórz Data.xls Client.
Kliknij kartę Arkusz 1 lub F4, aby aktywować ostatni arkusz roboczy. Kliknij SigmaXL & gt; Narzędzia statystyczne & gt; Statystyki opisowe.
Zaznacz pole wyboru "Użyj całej tabeli danych".
Kliknij "Dalej".
Należy wybrać "Total satysfakcją" naciśnij "danych numerycznych zmienny" (R).
Wybierz "rodzaj klienta" Press "Grupa Kategoria" (X1). Domyślny poziom ufności wynosi 95%.
Kliknij OK.
wykazali, że 95% przedział ufności oznacza Średni wierny parametr populacji (średnia, odchylenie standardowe i współczynnik) będzie w zakresie od 19 razy na 20. Będzie prezentowane użytkownikowi, odpowiadają 95% przedział ufności dla każdej ramki. Średnia (95% CI). 95% przedział ufności odchylenie standardowe (95% CI: Sigma - nie mylić z poziomem jakości Sigma procesu).
Statystyka i poziom ufności
Przedział ufności nie jest liczbą, w której prawdziwa wartość z dokładnością znaleźć. Rzeczywiście, teoretyczna wartość losowa może przyjmować wszystkie możliwe wartości w ramach praw fizyki. przedział ufności - w rzeczywistości jest obszarem, w którym prawdziwe (nieznany parametr ramach badania w populacji najprawdopodobniej prawdopodobieństwo, że wybrany Podczas korzystania interwał na podstawie obliczenia współczynnika progu zaufania, niepewność i bezpieczeństwa Przed zdefiniować przedział ufności.. Excel, te elementy, które są zależnez parametrów:
Zmienność mierzonych cech.
Wielkość próbki: im większa, tym wyższa precyzja.
Metody pobierania próbek.
Poziom zaufania - s.
Poziom zaufania jest gwarancją zaufania. Na przykład z poziomem ufności 90% oznacza to, że 10% ryzyka będzie błędne. Z reguły 95% przedział ufności jest dobrą praktyką. Zatem maksymalny poziom ufności jest większy, im większy jest rozmiar próbki. Współczynnik marginesu jest wskaźnikiem wyprowadzanym bezpośrednio z progu zaufania. Tabela zawiera przykłady najczęściej używanych wartości.
Poziom zaufania s
Wskaźnik depozytów zabezpieczających w n & gt; 30
80%
128
85%
(65 ) 144
90%
1645
95% 80)
196
96%
205
98%
233
99%
2575
Wskaźniki obliczyć
W przypadku gdy konieczne jest oszacowanie średniej wartości populacji z jej próbki, należy określić przedział ufności. To zależy od wielkości próbki i prawa zmiennej. Wzór obliczania przedziału ufności w programie Excel wygląda następująco:
Dolny przedział graniczny = średni bieg - współczynnik pola * standardowy błąd.
Górna granica zakresu = przybliżona średnia + współczynnik pola * błąd standardowy.
Wartość t zależeć będzie od wielkości próbki: n & gt; 30: współczynnik zapasów normalnego prawa, zwany z. n W tej sytuacji znajdują się same jednostkiśrednie wartości. Badacz będzie musiał znać odchylenie standardowe nie od początkowych i indywidualnych obserwacji, ale od funduszy, które są obliczane na ich podstawie. To odchylenie ma nazwę - standardowy błąd średniej.
Błędy
Zmienność danych jest używana na wykresach w celu wskazania błędu lub niepewności pomiaru. Dają ogólne pojęcie o tym, jak dokładne są pomiary, lub odwrotnie, jak daleko od podanej wartości rzeczywistej i są sporządzane w postaci pasm błędów. Reprezentują one jedno standardowe odchylenie niepewności, jeden błąd standardowy lub zdefiniowany przedział ufności (na przykład przedział 95%). Te wartości nie są zgodne, więc wybrana miara powinna być wskazana na wykresie lub w tekście. Pasma błędów można wykorzystać do porównania dwóch wartości, jeśli spełnione są warunki istotne statystycznie. Linie błędu wskazują na akceptowalność funkcji, to znaczy, jak dobrze opisuje dane. Prace naukowe w dziedzinie nauk eksperymentalnych zawierają błędy we wszystkich wykresach, chociaż praktyka jest nieco inna, a każdy badacz ma swój własny styl błędów. Pasma błędów mogą być używane jako bezpośredni interfejs do sterowania algorytmami probabilistycznymi do obliczeń zgrubnych. Pasma błędów można wyrazić jako znak plus lub minus (±). Plus to górny limit, a minus to dolny limit błędu.
Kalkulator wartości krytycznych
Dla prawidłowego zdefiniowania CI istnieją kalkulatory online, które są znaczącouprość pracę. Rozpocznie się proces określania zbierania danych. Jest podstawą wszystkich badań. Niezawodna próbka pomaga w podejmowaniu decyzji biznesowych w sposób pewny. Pierwszą kwestią, którą należy się zająć, jest poprawna definicja grupy docelowej, która ma kluczowe znaczenie. Jeśli badacz przeprowadzi ankietę wśród osób spoza tej grupy - nie uda się pomyślnie ukończyć zadania. Kolejnym krokiem jest ustalenie, ile osób musi przeprowadzić wywiad.
Eksperci wiedzą, że niewielka próbka reprezentatywna odzwierciedla myśli i zachowanie grupy, z której została skompilowana. Im większa próbka, tym dokładniej reprezentuje ona grupę docelową. Niemniej jednak szybkość poprawy dokładności maleje wraz ze wzrostem wielkości próbki. Na przykład zwiększenie z 250 do 1000 podwaja dokładność. Wybierz rozmiar próbki na podstawie takich czynników jak: dostępny czas, budżet i wymagany stopień dokładności. Istnieją trzy czynniki, które określają wielkość sztucznej inteligencji dla tego poziomu pewności:
wielkość próby;
procent próbki;
wielkość populacji.
Jeżeli 99% respondentów odpowiedziało "Tak", a 1% powiedziało "Nie", prawdopodobieństwo popełnienia błędu jest niewielkie, niezależnie od wielkości próbki. Jednakże, jeśli procent wynosi 51 i 49%, prawdopodobieństwo błędu jest znacznie wyższe. Łatwiej być pewnym ekstremalnych odpowiedzi niż średnia. Przy ustalaniu wielkości próbki wymaganej dla danego poziomu dokładności należy użyć najgorszego procentu (50%). Poniżej znajduje się wzór do obliczania przedziału ufności w wielkości próby programu Excelkalkulator online.
Przedmiotem przedział ufności Obliczenia sugerują, że prawdziwa próba losowa ludności zainteresowana. Jeśli ankieta nie jest losowa, nie możesz polegać na interwałach. Próbki nielosowe zwykle powstają z powodu niedociągnięć w procedurze.
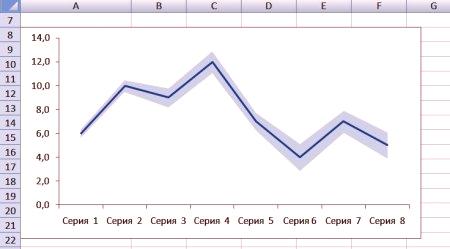
powstaje liniowy wykres
Tworzenie wykres w programie EXCEL przedział ufności jest stosunkowo proste. Najpierw utwórz diagram liniowy. Następnie wybierz "Narzędzia diagramów" & gt; Układ & gt; Panel błędów & gt; "Zaawansowane opcje panelu". W wyskakującym menu dialogowym można wybrać dodatnie lub ujemne paski błędów lub jedno i drugie. Możesz wybrać styl i wybrać kwotę, którą chcesz wyświetlić. Może to być stała wartość, procent, odchylenie standardowe lub niestandardowy zakres.
Jeżeli dane jest odchylenie standardowe domyślnie dla każdego punktu, wybierz interfejs i kliknij „Wyznacz wartość.” Wtedy nie ma innego menu pop-up, aby wybrać zakres komórek, zarówno pozytywnych jak i negatywnych paneli.
Kolejność budowy wykresu:
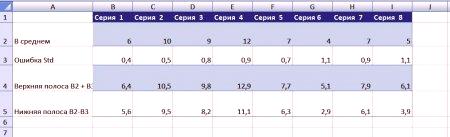
Przygotuj dane. Po pierwsze, w uzupełnieniu do średnich wartości należy obliczyć odchylenie standardowe (lub błędu).
, następnie linia 4 potrzeba obliczenia górnej granicy tej grupy, czyli obliczenie B4: = B2 + B3 linii 5 potrzebę obliczania dolnej granicy zakresu, czyli obliczenie B5: = B2, B4
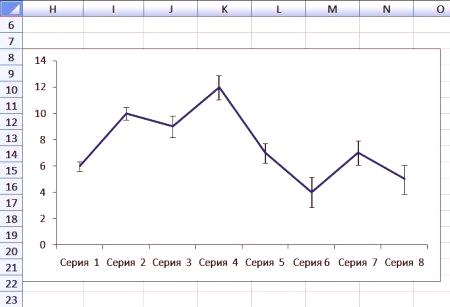
(131 ) Utwórz harmonogram. Zaznacz rzędy 124 i 5 tabeli, a następnie kliknij "Wklej" & gt; Zaplanuj & gt; "Diagram kołowy".Excel utworzy liniowy diagram.
Usuń legendę i linię siatki.
Następnie kliknij prawym przyciskiem myszy górną grupę zakresów i wybierz "Zmień typ wykresu".
Zakresy ufności formatu. Aby ukończyć wykres, po prostu sformatuj górną serię niebieskim wypełnieniem (zgodnie z niebieską linią), a dolną serię - białym wypełnieniem.
Na tym wykresie łatwo jest dostrzec granice błędów, ale w przypadku dużej ilości danych wygląd będzie losowy. Na pierwszy rzut oka, granica pewności jest bardziej oczywista, biorąc pod uwagę średnią wartość próbki, i będzie coraz bardziej napięta wraz ze wzrostem liczby próbek