Rozproszony system plików działa jako specjalny system, który wykonuje dostęp do plików w sieci, zapewnia dostęp i przechowywanie danych na większości maszyn serwerowych. Analogiem platformy sieciowej jest tradycyjny lokalny system plików, który zarządza urządzeniami pamięci masowej obsługiwanymi na komputerze PC.
Podstawy sieciowych baz danych
Te elementy odnoszą się do systemów plików sieciowych i gwarantują dostęp do nich na serwerach. Dzięki ich wsparciu użytkownik ma możliwość utworzenia integralnego systemu plików firewall. Zawiera różne narzędzia dla serwerów. Rozproszone systemy plików (RFS) zapewniają tworzenie kopii lustrzanych, replikację i tworzenie kopii zapasowych bazy danych na dowolnym dysku, dzięki czemu programista może edytować własne pliki, usuwać lub zapisywać konfiguracje.
Istnieje kilka RFU różniących się aplikacją, interfejsem i protokołami, a także różne funkcje, takie jak buforowanie, rejestrowanie, wielokanałowe wykorzystanie w sieciach lokalnych. Ponieważ przepustowość rozproszonych systemów plików dla klastrów jest bardzo niska, programy te mają specjalne systemy o szybkości transmisji powyżej 100 MB /s. Należą do nich system globalny (GFS) i zastrzeżony system ogólny (GPFS). RFU ma strukturę hierarchiczną i ma jedną logiczną umowę dotyczącą nazw. Jest to protokół sieciowy, który umożliwia użytkownikowi dostęp do plików bez znajomości lokalizacji serwera. Centralna struktura drzewa upraszczaSzukaj plików w całej firmie. Są przechowywane nadmiernie i całkowicie dostępne nawet w przypadku awarii głównego dysku twardego. Mówiąc szerzej, RFU jest rozumiane jako protokół sieciowy do uzyskiwania dostępu do systemu plików.
Przykładami są:
Network File System (NFS).
Wspólny system plików w Internecie (CIFS), rozbudowa jednostek serwerów wiadomości (SMB).
Apple Apple Filing Protocol (AFP).
Podstawowy protokół NetWare (NCP) firmy Novell.
Dobrze znane implementacje RFS to:
DFS w Windows od Microsoftu. Rozproszony system plików DFS ze standardem Microsoft w systemach operacyjnych serwerów. Po raz pierwszy pojawił się w Windows NT4 i został dostarczony z Windows 2000 Server. W systemie Windows Server 2003 do serwera dodano ulepszenia, takie jak kilka katalogów DFS.
AFS Andrew File System, dla którego w ramach projektu "Distributed Computing" jest kilku producentów.
Konsorcjum DCE Open Group, jako dalszy rozwój AFSCoda, zostało opracowane na Uniwersytecie Carnegie Mellonalosk.
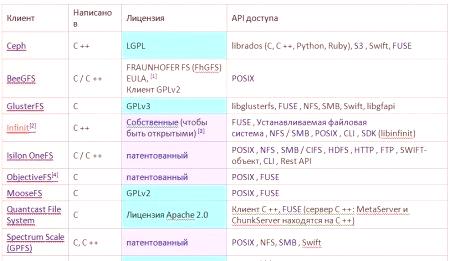
Klastry i aplikacje BeeGFS /FhGFS for HPCGlusterFS dla wszystkich systemów operacyjnych zgodnych z POSIX.
System plików Hadoop oferuje obiekty, repozytorium bloków i plików, część jądra Linux, LGPL.XtreemFS, odporny na awarie RFS z interfejsem zgodnym z POSIX.
System plików Google (GFS, GoogleFS) oparty na systemie Linux jest zoptymalizowany pod kątem danych o dużej przepustowości.
Porównanie rozproszonych systemów plików.
Utrzymanie i rodzaje usług systemowych
Taki system zapewnia następujące usługi:
Utrzymanie repozytorium. Dystrybucja i zarządzanie przestrzenią nawtórne urządzenie pamięci masowej, zapewniając logiczny wygląd systemu pamięci masowej.
Prawdziwa konserwacja plików. Obejmuje semantykę udostępniania plików, mechanizm buforowania, replikację, kontrolę równoległą, protokół kopiowania wielu kopii.
Usługa nazw katalogowych. Odpowiedzialny za działania związane z katalogiem: tworzenie i usuwanie katalogów, dodawanie nowego pliku do katalogu, usuwanie z katalogu, zmiana nazwy, przenoszenie z jednego katalogu do drugiego.
Wymagane funkcje RFU:
Przejrzystość. Klienci rozproszonego systemu plików DFS nie powinni znać liczby ani lokalizacji serwerów plików i urządzeń pamięci masowej. Wiele serwerów plików zapewnia wydajność, skalowalność, niezawodność i przejrzystość dostępu.
Zarówno pliki lokalne, jak i zdalne powinny być dostępne w ten sam sposób. System powinien automatycznie znaleźć dostępne i przenieść je na stronę klienta. Nazwa pliku nie powinna wskazywać lokalizacji pliku. Nie powinno się zmieniać po przejściu z jednej witryny do drugiej. Jeśli plik jest replikowany na wielu węzłach, obecność wielu kopii i ich lokalizacja powinny być ukryte przed klientami.
Mobilność automatycznie uruchamia środowisko użytkownika, na przykład katalog domowy użytkownika, do strony, w której jest zalogowany.
Produktywność mierzona jest jako średni czas potrzebny na spełnienie żądań klientów. Ten czas obejmuje czas procesora + czas dostępu do drugiego miejsca przechowywania + czas dostępu dosieć. Pożądane jest, aby wydajność rozproszonego systemu plików Windows była porównywalna z wydajnością scentralizowanego systemu.
Interfejs użytkownika w systemie jest prosty, jednak liczba poleceń powinna być jak najmniejsza.
Skalowalność, wzrost węzłów i użytkowników nie powinny poważnie zakłócać usługi.
Wysoka dostępność RFU powinna nadal działać w częściowych awariach, takich jak awaria komunikacji, węzeł lub napęd i powinna mieć kilka niezależnych serwerów plików, które zarządzają wieloma urządzeniami pamięci masowej.
Wysoka niezawodność. Prawdopodobieństwo utraty przechowywanych danych należy zminimalizować. System powinien automatycznie wykonywać kopie zapasowe ważnych plików.
Integralność danych zapewnia równoległość żądań wielu użytkowników dostępu, którzy ubiegają się o dostęp, i muszą być odpowiednio zsynchronizowane przy użyciu mechanizmu kontroli wielu form.
Użytkownicy muszą mieć pewność co do poufności swoich danych.
Niejednorodność RFU powinna zapewniać łatwy dostęp do wspólnych danych na różnych platformach, takich jak stacja robocza Unix, platforma Wintel i inne.
Model przeniesienia na poziomie bloków
W systemach plików, które korzystają z modelu buforowania danych, ważnym problemem projektowym jest wybór jednostki danych. Odnosi się to do części pliku, który jest przesyłany i tworzony przez klientów w wyniku jednej operacji odczytu lub zapisu. UModele transferu plików na poziomie pliku, gdy dane mają być przesyłane, cały plik jest przenoszony. Zalety modelu:
Plik powinien zostać wysłany tylko jeden raz w odpowiedzi na żądanie klienta, a zatem jest bardziej wydajny niż przenoszenie stron, wymagający większej liczby protokołów sieciowych.
Zmniejsza obciążenie serwera i ruch sieciowy, ponieważ tylko raz uzyskuje dostęp do serwera.
Poprawia to skalowalność. Gdy cały plik jest buforowany w witrynie klienta, nie reaguje na awarie serwerów i sieci.
Wady modelu:
Potrzebujesz wystarczającej ilości miejsca na komputerze klienta. Takie podejście nie jest odpowiednie dla bardzo dużych plików, szczególnie gdy klient pracuje na stacji roboczej bezdyskowych.
Tylko niewielka część pliku, przenoszenie całego pliku, jest marnotrawstwem.
Przekazywanie plików odbywa się w blokach. Jest to oddzielna jej część, ma stałą długość i może równać się wielkości strony pamięci wirtualnej.
W przypadku modelu przesyłania jednostka nadawcza jest bajtem. Model zapewnia maksymalną elastyczność, ponieważ pozwala zapisać i wyodrębnić dowolny rozmiar pliku, ustalony na podstawie wewnętrznej pojemności i długości. Wadą jest to, że zarządzanie pamięcią podręczną jest trudniejsze ze względu na dane o zmiennej długości dla różnych zapytań dostępu.
Model transferu na poziomie rekordu jest używany w przypadku plików strukturalnych, a jednostka przekazu jest rekordem. Kilku użytkowników może uzyskać dostęp do udostępnionego pliku w tym samym czasie. Ważny problemProjektowanie dla dowolnego systemu plików polega na określeniu, kiedy zmiany w plikach danych dokonane przez użytkownika są obserwowane przez innych użytkowników.
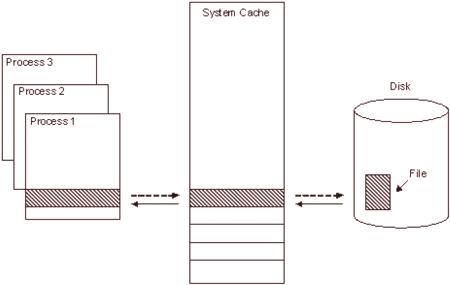
Formy i lokalizacja pamięci podręcznej
Każdy rozproszony system plików Windows używa swojej pamięci podręcznej. Przyczyny utworzenia pamięci podręcznej:
Najlepsza wydajność, ponieważ powtarzające się wywołania tej samej informacji są przetwarzane przez dodatkowy dostęp do sieci i dyski.
Wynika to z lokalizacji w szablonach dostępu do plików.
Przyczynia się do skalowalności i niezawodności RFU, ponieważ dane mogą być zdalnie buforowane na stronie klienta.
Najważniejsze decyzje, które należy podjąć w schemacie pamięci podręcznej plików dla RFS:
Lokalizacja pamięci podręcznej.
Modyfikacja dystrybucji.
Sprawdzanie pamięci podręcznej.
Lokalizacja pamięci podręcznej odnosi się do buforowanej lokalizacji przechowywania danych. Zakładając, że oryginalna lokalizacja pliku na dysku jego serwera. W RFS istnieje kilka możliwych lokalizacji pamięci podręcznej:
Główna pamięć serwera. W tym przypadku pamięć podręczna ma jeden dostęp do sieci. Nie pomaga to w skalowalności i niezawodności systemu, ponieważ każda pamięć podręczna kliknięć wymaga dostępu do serwera. Zalety metody - łatwość implementacji, przejrzystość dla klientów, prostota zapisywania pliku źródłowego w pamięci podręcznej.
Podczas korzystania z dysku klienta pamięć podręczna uzyskuje jeden dostęp do dysku. Jest to nieco wolniejsze niż posiadanie pamięci podręcznej w głównej pamięci serwera. Korzyści płynące z rozproszonych systemów plików przy korzystaniu z dysku klienta zapewniająniezawodność od awarii, ponieważ zmiana danych w pamięci podręcznej jest tracona w przypadku awarii. Ta wersja dużej pojemności, ułatwia skalowalność i niezawodność, ponieważ w pamięci podręcznej żądanie dostępu zdalnego może być obsługiwane lokalnie bez potrzeby kontaktowania się z serwerem.
Modyfikacja dystrybucji
Gdy pamięć podręczna znajduje się w węzłach klienta, dane pliku mogą być buforowane jednocześnie na wielu węzłach. Możliwe, że pamięci podręczne staną się nieskoordynowane, gdy dane pliku zostaną zmienione przez jednego z klientów, a odpowiednie dane buforowane w innych węzłach nie zostaną zmienione ani odrzucone. Występują dwa problemy projektowe:
Podczas dystrybucji zmian wprowadzonych do tych danych na odpowiednim serwerze plików.
Sprawdzając autentyczność zapisanych w pamięci podręcznej danych.
Zastosowany schemat rozkładu modyfikacji ma krytyczny wpływ na wydajność i niezawodność systemu. Metoda "Schemat nagrywania" jest używana, gdy wpis w pamięci podręcznej zostanie zmieniony, nowa wartość zostanie natychmiast wysłana do serwera w celu zaktualizowania głównej kopii pliku. Zaletą tej metody jest wysoki stopień niezawodności i przydatności do semantyki podobnej do UNIX. Wynika to z faktu, że ryzyko odzyskania danych utracone w przypadku awarii klienta jest bardzo niskie, ponieważ każda modyfikacja natychmiast odnosi się do serwera, który ma kopię główną. Brak - ten schemat jest odpowiedni tylko wtedy, gdy stosunek trafień do odczytu rekordu jest wystarczająco duży. Nie zmniejsza ruchu sieciowego do pisania. Wynika to z faktu, że każdy dostęp do zapisu powinien czekać, aż dane zostaną zapisane na głównej kopii serwera.
Schemat zopóźnienie nagrywania
Aby zmniejszyć ruch sieciowy podczas zapisu, używany jest schemat opóźnień nagrywania. W tym przypadku nowa wartość danych jest zapisywana tylko w pamięci podręcznej, a wszystkie zaktualizowane rekordy pamięci podręcznej są wysyłane później do serwera. Istnieją trzy najczęściej stosowane podejścia dotyczące opóźnień nagrywania:
Nagrywanie po wypchnięciu z pamięci podręcznej. Zmodyfikowane dane w pamięci podręcznej są wysyłane na serwer tylko wtedy, gdy zasady wymiany pamięci podręcznej zdecydowały się wyodrębnić dane z pamięci podręcznej. Może to prowadzić do dobrej wydajności, ale może występować problem z niezawodnością, ponieważ niektóre dane serwera ulegają starzeniu przez długi czas.
Okresowe nagrywanie. Pamięć podręczna jest okresowo sprawdzana, a wszelkie buforowane dane, które zostały zmodyfikowane od czasu ostatniego skanowania, zostały wysłane na serwer.
Zamknięcie. Modyfikacja buforowanych danych jest wysyłana do serwera, gdy klient zamyka plik. To niewiele pomaga w ograniczaniu ruchu sieciowego w przypadku plików, które są otwarte w bardzo krótkim czasie lub rzadko się zmieniają.
Zalety schematu opóźnionego zapisu:
Rekord dostępu jest wykonywany szybciej, ponieważ nowa wartość jest zapisywana tylko w pamięci podręcznej klienta. Prowadzi to do zwiększenia wydajności.
Zmodyfikowane dane można usunąć, zanim nadejdzie czas ich wysłania na serwer, na przykład dane tymczasowe. Ponieważ modyfikacje nie muszą być stosowane na serwerze, prowadzi to do znacznego wzrostu wydajności.
Zbieranie wszystkich aktualizacji plików i wysyłanie ich na serwer jest wydajniejsze niż wysyłanie każdej aktualizacji indywidualnie.
Brak schematu opóźnionego rekordem - niezawodność wciąż może być problematyczna, ponieważ zmiany wysłane na serwer z pamięci podręcznej klienta zostaną utracone.
Replikacja jako mechanizm dostępności
Wysoka dostępność jest dobrą funkcją rozproszonego systemu plików, a replikacja plików jest głównym mechanizmem poprawiającym dostępność plików. Plik replikowany jest plikiem, który ma wiele kopii, każda z osobnym serwerem. Różnica między replikacją a buforowaniem
Replika pliku jest powiązana z serwerem, podczas gdy kopia w pamięci podręcznej jest zwykle powiązana z klientem.
Istnienie kopii w pamięci podręcznej zależy przede wszystkim od lokalizacji w szablonach dostępu do plików, podczas gdy obecność repliki zwykle zależy od wymagań dotyczących dostępności i wydajności.
W porównaniu z kopią buforowanej repliki jest bardziej trwały, powszechnie znany, bezpieczny, dostępny, kompletny i dokładny.
Kopia w pamięci podręcznej zależy od repliki. Tylko kopia w pamięci podręcznej może być przydatna podczas okresowego sprawdzania repliki.
Zalety replikacji:
Zwiększona dostępność. Alternatywne kopie replikowanych danych mogą być używane, gdy kopia główna jest niedostępna.
Zwiększona niezawodność. Ze względu na obecność nadmiarowych plików danych, możliwe jest odzyskanie danych po katastrofalnych awariach, na przykład awarii dysku twardego.
Poprawiony czas reakcji. Umożliwia dostęp do danych lokalnie lub z węzła, którego czas dostępu jest krótszy niż czas dostępu do oryginalnej kopii.
Zmniejsz ruch w sieci. Jeśli replika plików jest dostępna z serwerem plików zlokalizowanym w witrynie klienta, żądanie dostępu klienta może być obsługiwane lokalnie, co zmniejsza ruch sieciowy.
Poprawiona przepustowość systemu. Wiele żądań klienta dotyczących dostępu do pliku może być obsługiwanych równolegle na różnych serwerach, co zwiększa przepustowość systemu.
Lepsza skalowalność. Dostępnych jest kilka serwerów obsługujących żądania klientów z powodu replikacji plików. Poprawia to skalowalność.
Ustawienie klienta podczas odłączania
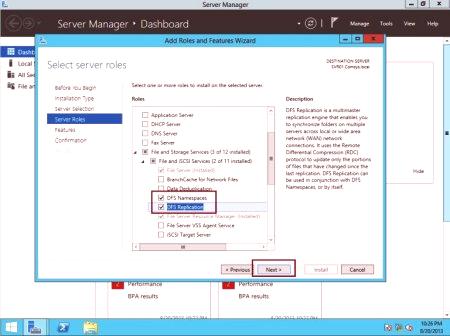
Często problem z systemem jest pojawienie się komunikatu DFS „Disconnected Klient Distributed File systemu DFS». Microsoft musi rozwiązać ten problem, aby to zrobić, musisz włączyć klienta na serwerze, na przykład Windows Server 2012 R2. Algorytm działania:
Otwórz Menedżera serwera i wybierz „Zarządzanie systemem plików DFS” w sekcji „Narzędzia”, jeśli nie można go znaleźć, trzeba dodać funkcję DFS nazw.
Kliknij myszą i wybierz kreator "New Namespace".
Należy określić nazwę hosta, aby zadzwonić do obszaru nazw systemu plików DFS rozpowszechniany.
Kliknij "Utwórz" i obszar DFS.
Obejmuje foldery współdzielone w systemie plików DFS.
Wybierz przestrzeń nazw i kliknij folder Nowy folder.
Scalanie wielu folderów w unikalny folder wirtualny.
może być utworzona przez Domain_NameNamespace_NameVirtual_folder_name widoczne.
, a następnie komunikat „Usługa nie rozproszony system plikówzainstalowane ", nie będzie już więcej.
System udostępniania zasobów sieciowych w systemie Linux
NFS jest najczęstszym systemem plików do udostępniania zasobów sieciowych. Najpopularniejszą wersją jest NFS v2. Ten rozproszony system plików Linux zachowuje się jak najwyższy poziom lokalnego systemu plików. Dostęp do zdalnych plików odbywa się za pośrednictwem procedur RPC. Nie dba o status serwera dostępny lub niedostępny i wykorzystuje bardzo niewiele technologii buforowania. Ponadto bezpieczeństwo tego systemu opiera się na zaufaniu klienta. Rzeczywiście, jest to identyfikator klienta, który jest przekazywany w celu zapoznania się z prawami dostępu do zasobów. NFS v3 jest rozwinięciem NFS i jest obecnie używane w dzisiejszym opatentowanym systemie Unix, który wypełnia niektóre luki w tym drugim. Ta definicja rozproszonego systemu plików pozwala strukturalnie obsługiwać duże pliki o rozmiarze 264 bitów, a także sprawdzać prawa dostępu na serwerze. Mogą być oparte na tradycyjnym uwierzytelnianiu systemu Unix lub używać dodatkowego uwierzytelniania, takiego jak Kerberos. Wersja zapewnia możliwość asynchronicznego zapisu danych, co zapewnia lepszą wydajność. Jednak większość innych operacji pozostaje synchroniczna. Obsługa NFS v3 znajduje się obecnie w fazie eksperymentalnej jądra systemu Linux i jest bardzo efektywna.
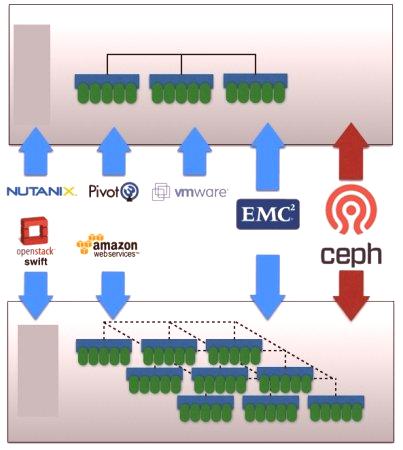
Skalowane przechowywanie bloków
Ceph to oprogramowanie zaprojektowane w celu zapewnienia skalowalnego repozytorium obiektów, bloków i plików w systemie. Klastry do przechowywaniaRozproszony system plików Ceph został zaprojektowany do pracy na sprzęcie towarowym przy użyciu algorytmu CRUSH w celu zapewnienia równomiernego rozkładu danych klastra, wtedy wszystkie węzły w klastrze mogą szybko odbierać dane bez żadnych scentralizowanych wąskich gardeł. Ceph jest dostępny przez Amazon Simple (S3) i OpenStack Swift (REST) w oparciu o interfejsy programowania aplikacji oraz natywny interfejs API do integracji z aplikacjami. Pamięć masowa Ceph używa blokady, która jest dyskiem wirtualnym i może być podłączona do serwerów opartych na systemie Linux lub wirtualnych maszyn o otwartym kodzie źródłowym. Zaufane samodzielne repozytorium obiektów rozproszonych Ceph (RADOS) udostępnia funkcje przechowywania, takie jak migawki i replikacja. Urządzenie blokujące Ceph RADOS jest zintegrowane, aby działać jako część tylna z magazynem blokowym OpenStack. Repozytorium plików Ceph wykorzystuje system plików POSIX zgodny z CephFS (CephFS) do przechowywania danych w klastrze pamięci Ceph. CephFS używa tego samego systemu klastrowego co repozytorium bloków Ceph i repozytorium Ceph.
Korzyści z rozproszonego systemu plików
Technicznie zapewnia dostęp do ogólnego katalogu, który nie zawiera plików, ale tylko przejścia i opcjonalne podkatalogi z dużą liczbą przejść. Przejścia są podobne do miękkich łączy, znanych z systemu plików Unix, ale odnoszą się do wspólnych katalogów i mogą wskazywać na wspólne katalogi na innych serwerach. Najpierw klienci pytają serwer DFS o połączenie, a następnie kontaktują się z serwerem, do którego prowadzi połączenie.Podstawowym celem używania rozproszonego systemu plików DFS jest utworzenie alternatywnej przestrzeni nazw (reprezentacji drzewa katalogów), która ukrywa przed użytkownikiem szczegóły dotyczące infrastruktury bazowej. Ścieżki, które użytkownicy widzą i wywołują nazwy DFS, nie zmieniają się podczas zmiany nazwy serwerów lub przenoszenia niektórych katalogów na inny serwer. Administratorzy mogą po prostu zamienić przestarzałą nazwę na nową, która wskazuje na nowy cel. Nazwa może określać więcej niż jeden cel, tzn. Zapewnia kilka alternatywnych połączeń z klientem dla różnych folderów współdzielonych. W takim przypadku klienci rozproszonego systemu plików DFS mogą uzyskać dostęp do dowolnych celów. Zapewnia to równoważenie obciążenia i automatyczne przełączanie na inny serwer w przypadku awarii jednego z serwerów. Dzięki DFS nie ma już ścisłego połączenia z serwerem. Pamięć jest reprezentowana jako pula o dużej pojemności, za którą ukryte są systemy plików dla użytkownika. W rzeczywistości jest to niezwykle użyteczne narzędzie do sprostania rosnącym wymaganiom, że system plików dystrybuuje przestrzeń dyskową nowych serwerów w oparciu o wymagania dotyczące dostępności. Technologia, taka jak Windows DFS, jest korzystna dla każdej firmy, zarówno dużej, jak i małej. W przypadku dużych firm aspekt elastyczniejszego wykorzystania zasobów pamięci masowych się opłaca. Ponieważ wszystkie dyski są częścią pamięci wirtualnej, nie ma więcej nieużywanych lub przepełnionych dysków i macierzy. Mniejsze firmy doceniają jednak standaryzację administracji. Dzięki jejOgraniczone zasoby trudno jest śledzić pełne serwery, aktualizować je w odpowiednim czasie do dużych dysków i rozpowszechniać przestrzeń między aplikacjami. System plików DFS nie reprezentuje przestrzeni dyskowej w taki sposób, że użytkownicy i aplikacje chcą ją zobaczyć, ponieważ tak naprawdę istnieje. A ponieważ serwer i komponent klienta są integralną częścią systemu operacyjnego Windows, proces instalacji i konfiguracji wymaga niewielkiego wysiłku ze strony administratora i praktycznie nie ma wpływu na działanie użytkowników. Deweloperzy zintegrowali pełne zarządzanie rozproszonym systemem plików DFS Windows, konsola jest jednym punktem kontrolnym dla kilku systemów DFS z systemem głównym. Narzędzia graficzne ułatwiają przeglądanie i monitorowanie. Zarządzanie jest możliwe nawet na stronach internetowych.