Unicode to międzynarodowy standard kodowania znaków, który umożliwia wyświetlanie tekstu na dowolnym komputerze na świecie w ten sam sposób, niezależnie od używanego języka systemu.
Podstawy
Aby zrozumieć, do czego jest wymagana tabela znaków Unicode, najpierw zrozumiemy mechanizm wyświetlania tekstu na ekranie monitora. Komputer, jak wiemy, przetwarza wszystkie informacje w formie cyfrowej, ale aby wydobyć je w celu prawidłowego postrzegania osoby, musi ona znajdować się w grafice. Abyśmy mogli przeczytać ten tekst, musimy rozwiązać co najmniej dwa zadania:
Zakodować drukowane znaki w postaci cyfrowej.
Włącz system operacyjny, aby porównać formę cyfrową z symbolami wektorowymi, innymi słowy, aby znaleźć właściwe litery.
Pierwsze kodowanie
Poprzednikiem wszystkich kodowań jest amerykański kod ASCII. Opisał alfabet angielski z interpunkcją i cyframi arabskimi. Wykorzystane w nim 128 znaków stało się podstawą do dalszego rozwoju - wykorzystywana jest nawet nowoczesna tablica znaków Unicode. Litery alfabetu łacińskiego zajmują od tego czasu pierwsze pozycje w dowolnym kodowaniu.
Wszystkie ASCII pozwoliły na zapisanie 256 znaków, ale ponieważ pierwszych 128 było łacińskich, pozostałe 128 było używanych globalnie do tworzenia norm krajowych. Na przykład w Rosji na jego podstawie powstały CP866 i KOI8-R. Odmiany te nazywane były rozszerzeniamiWersje ASCII.
Kodowane strony i Crazzybras
Dalszy rozwój technologii i pojawienie się interfejsu graficznego doprowadziły do stworzenia kodowania ANSI przez American Institute of Standardization. Dla rosyjskich użytkowników, zwłaszcza z doświadczeniem, jego wersja nosi nazwę Windows 1251. Najpierw wprowadzono pojęcie "strony kodowej". To było za pomocą stron kodowych, które zawierały symbole narodowych alfabetów, z wyjątkiem łaciny, istniało "wzajemne zrozumienie" między komputerami używanymi w różnych krajach.
Jednak obecność dużej liczby różnych kodowań używanych dla tego samego języka zaczęła powodować problemy. Były to tzw. Karkozybris. Wynikają one z rozbieżności między stroną kodu źródłowego, w której niektóre informacje zostały utworzone, a stroną kodową używaną domyślnie na komputerze użytkownika końcowego.
Jako przykład można przytoczyć wspomniane wyżej kodowania cyryliczne CP866 i KOI8-R. Litery w nich różniły się pozycjami kodowymi i zasadami umieszczania. W pierwszym uporządkowano je alfabetycznie, w drugim - w sposób arbitralny. Możesz sobie wyobrazić, co działo się na oczach użytkownika, który próbował otworzyć taki tekst bez posiadania żądanej strony kodowej lub błędnej jej interpretacji przez komputer.
Tworzenie Unicode
Rozprzestrzenianie się Internetu i powiązanych technologii, takich jak poczta elektroniczna, doprowadziło do tego, że wiadomości tekstowe przestały być odpowiednie dla wszystkich. Wiodące firmy w regionieStworzyła Unicode Consortium („Konsorcjum Unicode). Charakter reprezentował go w 1991 roku, zwany UTF-32 pozwoliło zachować więcej niż jeden miliard niepowtarzalny charakter. Był to ważny krok na drodze do rozszyfrowania tekstów.
Jednak pierwsza uniwersalna tabela kodów znaków Unicode UTF-32 nie była szeroko rozpowszechniana. Głównym powodem była nadmiarowość przechowywanych informacji. Szybko obliczono, że w przypadku krajów, które używają alfabetu łacińskiego, zakodowanych przy użyciu nowego uniwersalnego arkusza kalkulacyjnego, tekst zajmie cztery razy więcej miejsca niż przy użyciu rozszerzonej tabeli ASCII.
Opracowanie kodu Unicode
Poniższa tabela znaków UTF-16 Unicode rozwiązała ten problem. Kodowanie w nim odbywało się w połowie liczby bitów, ale jednocześnie zmniejszała się liczba możliwych kombinacji. Zamiast miliardów znaków może przechowywać tylko 65536. Jednak okazało się tak skuteczne, że liczba decyzją Konsorcjum zostało zdefiniowane jako podstawowy charakter przestrzeni magazynowej standardem Unicode. Pomimo tego sukcesu, UTF-16 nie pasował do wszystkich, ponieważ ilość przechowywanych i przesyłanych informacji wciąż była przytłoczona dwukrotnie. Uniwersalnym rozwiązaniem jest tablica znaków Unicode UTF-8 o zmiennej długości zapisu. Można to nazwać przełomem w tej dziedzinie.
Tak więc, wraz z wprowadzeniem dwóch ostatnich standardów, tablica znaków Unicode rozwiązała problem pojedynczej przestrzeni kodowej dla wszystkich obecnie stosowanych czcionek.
Unicode dla języka rosyjskiego
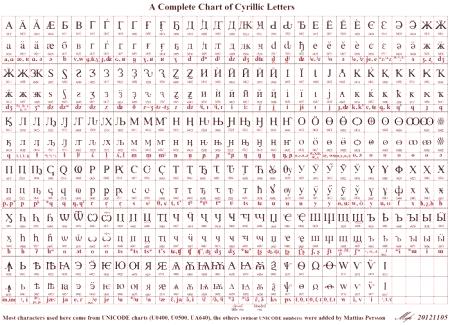
DziękiZmienna długość kodu używana do wyświetlania symboli, łacina jest kodowana w formacie Unicode, tak jak w jej wstępnym ASCII, czyli jednym bitem. W przypadku innych alfabetów obraz może wyglądać inaczej. Na przykład znaki alfabetu gruzińskiego są używane do kodowania trzech bajtów, a znaki alfabetu cyrylicy to dwa. Wszystko to jest możliwe w standardzie UTF-8 Unicode (mapa znaków). Język rosyjski lub cyrylica zajmuje 448 pozycji w ogólnej przestrzeni kodu, podzielonych na pięć bloków.
Te pięć bloków zawiera główne cyrylicy i alfabety słowiańskie, a także dodatkowe litery innych języków, które używają cyrylicy. Wiele pozycji jest podświetlonych, aby wyświetlić stare formy reprezentacji liter alfabetu cyrylicy, a 22 pozycje całkowitej kwoty pozostają bezpłatne.
Aktualna wersja Unicode
Decyzją o priorytetowym zadaniu, jakim była standaryzacja czcionek i stworzenie dla nich jednej przestrzeni kodowej, "Konsorcjum" nie zakończyło swojej pracy. Unicode stale się rozwija i uzupełnia. Najnowsza aktualna wersja tego standardowego 9.0 została wydana w 2016 roku. Zawierał on sześć dodatkowych alfabetów i rozszerzoną listę standardowych emoji. Należy zauważyć, że w celu uproszczenia badań do systemu Unicode dodano nawet tak zwane martwe języki. Mają takie imię, ponieważ ludzie, dla których był krewnym, nie istnieją. Do tej grupy należą również języki, które przetrwały do naszych czasów tylko w formie pisemnych pomników. Wzasadę, ubiegać się o dodanie znaków do nowej specyfikacji Unicode może każdy. To prawda, ponieważ będzie musiał wypełnić przyzwoitą ilość dokumentów źródłowych i spędzić dużo czasu. Żywym tego przykładem może być historia programisty Terence'a Edena. W 2013 r. Złożył wniosek o uwzględnienie w specyfikacji symboli odnoszących się do przycisków do zarządzania zasilaniem komputera. W dokumentacji technicznej były one używane od połowy lat 70. ubiegłego wieku, ale przed specyfikacją 9.0 nie było częścią Unicode.
Tablica znaków
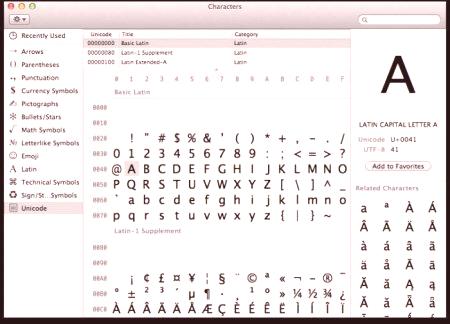
Na każdym komputerze, niezależnie od używanego systemu operacyjnego, tablica znaków Unicode. Jak korzystać z tych arkuszy kalkulacyjnych, gdzie je znaleźć i co mogą zrobić dla zwykłego użytkownika?
W systemie Windows tabela symboli znajduje się w sekcji menu "Usługi". W rodzinie systemów operacyjnych Linux zazwyczaj można go znaleźć w sekcji "Standard", aw MacOS - w ustawieniach klawiatury. Głównym celem tej tabeli jest wprowadzanie znaków w dokumentach tekstowych, które nie znajdują się na klawiaturze. Wniosek o takie stoły można uznać za szeroki: od wprowadzenia symboli technicznych i ikon krajowych systemów walutowych do napisania podręcznika praktycznego zastosowania kart tarota.
Podsumowując
Unicode jest używany wszędzie i wchodzi w nasze życie wraz z rozwojem Internetu i technologii mobilnych. Ze względu na jego wykorzystanie system komunikacji międzynarodowej znacznie się uprościł. Możesz tak powiedziećwprowadzenie Unicode jest orientacyjnym, ale całkowicie niewidocznym przykładem wykorzystania technologii dla wspólnego dobra całej ludzkości.