Przejście na kursy dotyczące promocji SEO, nowicjusze spotykają się z dużą ilością zrozumiałych i niezbyt punktualnych. Wszystko to nie jest łatwe do zrozumienia, zwłaszcza jeśli początkowo było to słabo wyjaśnione lub utracone niektóre chwile. Weź pod uwagę wartość pliku robots.txt Disallow, który wymaga tego dokumentu, jak go utworzyć i pracować z nim.
W prostych słowach
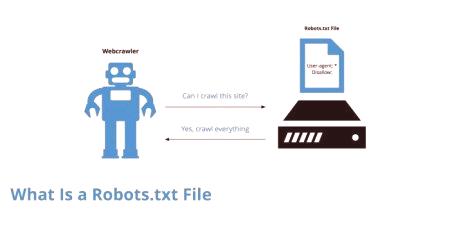
Aby nie "nakarmić" czytelnika złożonymi wyjaśnieniami, które zwykle znajdują się na wyspecjalizowanych stronach, lepiej wszystko wyjaśnić "na palcach". Wyszukiwarka dociera do Twojej witryny i indeksuje strony. Po wyświetleniu raportów wskazujących na problemy, błędy itp.
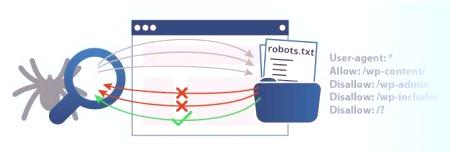
Ale strony mają również takie informacje, które nie są wymagane do statystyk. Na przykład strona "Firma" lub "Kontakty". Wszystko to jest opcjonalne w przypadku indeksowania, aw niektórych przypadkach jest niepożądane, ponieważ może zniekształcać statystyki. Aby tego uniknąć, najlepiej zamknąć te strony od robota. Dokładnie to wymaga polecenia w pliku robots.txt Disallow.
Standard
Ten dokument jest zawsze dostępny na stronach internetowych. Jego tworzenie zajmuje się programistami i programistami. Czasem może to również zrobić właściciel zasobu, zwłaszcza jeśli jest mały. W tym przypadku praca z nim nie zajmuje dużo czasu. Robots.txt jest nazywany standardem wykluczania wyszukiwarki. Przedstawia go dokument, w którym obowiązują główne ograniczenia. Dokument jest umieszczony w katalogu głównym zasobu. W takim przypadku, aby można go było znaleźć na ścieżce "/robots.txt". Jeślizasób ma kilka poddomen, a następnie plik ten znajduje się w katalogu głównym każdego z nich. Standard jest stale połączony z innym - Sitemaps.
Mapa strony
Aby zrozumieć pełny obraz tego, co jest omawiane, kilka słów o mapach witryn. To jest plik napisany w XML. Przechowuje wszystkie dane na temat zasobu dla PS. Według dokumentu można dowiedzieć się o stronach internetowych indeksowanych według utworów.
Plik zapewnia szybki dostęp do PS na dowolnej stronie, pokazuje najnowsze zmiany, częstotliwość i ważność PS. Zgodnie z tymi kryteriami robot najskuteczniej skanuje witrynę. Ale ważne jest, aby zrozumieć, że obecność takiego pliku nie gwarantuje, że wszystkie strony są indeksowane. Jest to raczej wskazówka na drodze do tego procesu.
Sposób użycia
Właściwy plik robots.txt jest używany dobrowolnie. Sam standard pojawił się w 1994 roku. Został zaakceptowany przez konsorcjum W3C. Od tego momentu zaczęto go używać w prawie wszystkich wyszukiwarkach. Jest to wymagane do "dozowanej" regulacji skanowania zasobów przez robota wyszukiwania. Plik zawiera zestaw instrukcji, które używają FP. Dzięki zestawowi narzędzi łatwo można instalować pliki, strony, katalogi, których nie można indeksować. Robots.txt wskazuje również na pliki, które należy natychmiast sprawdzić.
Dlaczego?
Pomimo faktu, że plik może faktycznie być używany dobrowolnie, jest tworzony przez praktycznie wszystkie witryny. Jest to wymagane w celu usprawnienia pracy robota. W przeciwnym razie sprawdzi wszystkie strony w losowej kolejności, a oprócz tego, że będzie w stanie pominąć niektóre strony, spowoduje to duże obciążeniezasób Ponadto plik służy do ukrycia się przed wyszukiwarką:
Strony z danymi osobowymi odwiedzających.
Strony zawierające formularze do przesyłania danych itp.
Witryny lustrzane.
Strony z wynikami wyszukiwania.
Jeśli podałeś plik robots.txt Disallow dla określonej strony, jest szansa, że nadal będzie on widoczny w wyszukiwarce. Ta opcja może wystąpić, jeśli link do strony zostanie umieszczony na jednym z zasobów zewnętrznych lub w witrynie.
Dyrektywy
Mówiąc o zakazie wyszukiwarki, często używa się terminu "dyrektywy". Ten termin jest znany wszystkim programistom. Często jest on zastępowany przez synonim "instrukcji" i używany w połączeniu z "poleceniami". Czasami może być reprezentowany przez zestaw konstrukcji języka programowania. Dyrektywa Disallow w pliku robots.txt jest jedną z najczęstszych, ale nie jedyną. Oprócz tego istnieje kilka innych, którzy są odpowiedzialni za niektóre instrukcje. Na przykład istnieje agent użytkownika, który wyświetla roboty wyszukiwarek. Allow to przeciwieństwo polecenia disallow. Wskazuje uprawnienia do indeksowania niektórych stron. Następnie przyjrzyjmy się podstawowym poleceniom.
Wizytówka
Oczywiście w pliku robots.txt User Agent Disallow nie jest jedyną dyrektywą, ale jedną z najczęstszych. Składa się z większości plików dla małych zasobów. Wizytówką dowolnego systemu jest nadal polecenie agenta użytkownika. Ta reguła ma wskazywać na roboty, które sprawdzają instrukcje, które zostaną zapisane w dokumencie. Obecnie jest 300 wyszukiwarek. Jeśli chcesz, aby każdy z nich podążałWedług niektórych wskazań, nie powinno się prawie wszystko przepisywać. Wystarczy podać "User-agent: *". "Asterisk" w tym przypadku pokaże systemy, które takie reguły są przeznaczone dla wszystkich wyszukiwarek. Jeśli tworzysz wskazówki dla Google, musisz podać nazwę robota. W takim przypadku użyj Googlebota. Jeśli w dokumencie zostanie podana tylko nazwa, inne wyszukiwarki nie zaakceptują poleceń pliku robots.txt: Disallow, Allow itd. Przyjmą, że dokument jest pusty i nie ma dla nich żadnych instrukcji.
Pełną listę botnames można znaleźć w Internecie. Jest bardzo długi, więc jeśli potrzebujesz instrukcji do niektórych usług Google lub Yandex, będziesz musiał podać konkretne nazwy.
Zakaz
Już wielokrotnie rozmawialiśmy o kolejnym zespole. Nie zezwalaj tylko określa, jakie informacje nie powinny być czytane przez robota. Jeśli chcesz wyświetlić wszystkie swoje treści w wyszukiwarkach, po prostu napisz "Disallow:". Tak więc praca będzie skanować wszystkie strony twojego zasobu. Całkowity zakaz indeksowania pliku robots.txt "Disallow: /". Jeśli napiszesz w ten sposób, to praca nie będzie skanować zasobu w ogóle. Zwykle odbywa się to na początkowych etapach, w przygotowaniu do uruchomienia projektu, w eksperymentach itp. Jeśli witryna jest gotowa do pokazania się, zmień tę wartość, aby użytkownicy mogli się z nią zapoznać. Ogólnie rzecz biorąc, zespół jest uniwersalny. Może blokować pewne przedmioty. Na przykład folder z komendą Disallow: /papka /może zabraniać przeszukiwania łącza do pliku lub dokumentów określonego uprawnienia.
Pozwolenie
Aby zezwolić na pracęprzeglądać określone strony, pliki lub katalogi za pomocą dyrektywy Allow. Czasami potrzebne jest polecenie, aby robot odwiedzał pliki z określonej sekcji. Na przykład, jeśli jest to sklep internetowy, możesz określić katalog. Inne strony zostaną przeskanowane. Pamiętaj jednak, że musisz najpierw zatrzymać przeglądanie całej zawartości witryny, a następnie określić polecenie Zezwól na otwarte strony.
Lustra
Inna dyrektywa w sprawie siedziby. To nie jest używane przez wszystkich webmasterów. Jest potrzebny, jeśli twój zasób ma lusterka. Ta reguła jest wymagana, ponieważ wskazuje na działanie "Yandex", na którym zwierciadło jest głównym i które musi zostać zeskanowane. System nie rozprasza się i łatwo znajduje wymagany zasób zgodnie z instrukcjami opisanymi w pliku robots.txt. W samym pliku strona jest napisana bez wskazania "http: //", ale tylko wtedy, gdy działa na HTTP. Jeśli używa protokołu HTTPS, wskazuje ten prefiks. Na przykład "Host: site.com", jeśli HTTP, lub "Host: https://site.com" w przypadku HTTPS.
Nawigator
Mówiliśmy już o mapach witryn, ale jako osobny plik. Patrząc na zasady pisania pliku robots.txt z przykładami, widzimy użycie podobnego polecenia. Plik odnosi się do "Sitemap: http://site.com/sitemap.xml". Odbywa się to w ten sposób, że robot sprawdza wszystkie strony, które są wymienione na mapie witryny pod adresem. Za każdym razem, gdy wrócisz, robot zobaczy nowe aktualizacje, zmiany, które zostały wprowadzone, i szybsze wysyłanie danych do wyszukiwarki.
Dodatkowe polecenia
Były to podstawowe wytyczne, które wskazują na ważne i niezbędne polecenia. Jest mniej użytecznych, iinstrukcje nie zawsze są używane. Na przykład opóźnienie indeksowania określa czas, jaki ma być używany podczas ładowania strony. Jest to wymagane w przypadku słabych serwerów, aby nie "umieszczać" ich w robotach. Sekundy służą do określenia parametru. Funkcja Clean-param pomaga uniknąć duplikowania zawartości zlokalizowanej pod różnymi adresami dynamicznymi. Powstają, jeśli istnieje funkcja sortowania. Będzie to wyglądało następująco: "Clean-param: ref /catalog/get_product.com".
Uniwersalny
Jeśli nie wiesz, jak utworzyć poprawny plik robots.txt - nie przerażaj. Oprócz instrukcji dostępne są wersje uniwersalne tego pliku. Można je umieścić na praktycznie dowolnej stronie internetowej. Wyjątek może być tylko doskonałym zasobem. Ale w tym przypadku pliki powinny być znane specjalistom i zaangażować je w specjalne osoby.
Uniwersalny zestaw dyrektyw umożliwia otwieranie zawartości witryny w celu indeksowania. Tutaj jest nazwa hosta i wskazana jest mapa strony. Umożliwia robotom zawsze dostęp do stron, które są wymagane do zeskanowania. Domyślamy się, że dane mogą się różnić w zależności od systemu, z którego korzysta twój zasób. Dlatego należy wybrać reguły, patrząc na rodzaj strony i CMS. Jeśli nie masz pewności, że plik, który utworzyłeś, jest poprawny, możesz go sprawdzić w Narzędziach Google dla webmasterów i Yandex.
Błędy
Jeśli rozumiesz, co Disallow oznacza w pliku robots.txt, nie gwarantuje to, że nie popełnisz błędów podczas tworzenia dokumentu. Istnieje wiele typowych problemów napotykanych przez niedoświadczonych użytkowników. Często mylą wartość dyrektywy. Być możewiąże się z nieporozumieniami i nieznajomością instrukcji. Być może po prostu to zignorowałeś i przerwałeś niedbalstwo. Na przykład mogą używać "/" dla User-agent, a dla Disallow nazwa to robot. Transfer to kolejny powszechny błąd. Niektórzy użytkownicy uważają, że lista zablokowanych stron, plików lub folderów powinna być wymieniona jedna po drugiej. W rzeczywistości, dla każdego zabronionego lub dozwolonego łącza, pliku i folderu, musisz napisać polecenie ponownie iz nowej linii. Błędy mogą być spowodowane niewłaściwą nazwą samego pliku. Pamiętaj, że nazywa się to "robots.txt". Użyj małej litery dla nazwy, bez zmian, takich jak "Robots.txt" lub "ROBOTS.txt".
Pole agenta użytkownika powinno być zawsze wypełnione. Nie zostawiaj tej dyrektywy bez polecenia. Powracając do hosta, pamiętaj, że jeśli witryna korzysta z protokołu HTTP, nie musisz jej określać w poleceniu. Tylko jeśli jest to zaawansowana wersja HTTPS. Nie można pominąć dyrektywy Disallow. Jeśli go nie potrzebujesz, po prostu go nie kieruj.
Wnioski
Podsumowując, warto powiedzieć, że robots.txt to standard, który wymaga dokładności. Jeśli nigdy go nie spotkałeś, to na wczesnym etapie tworzenia będziesz miał wiele pytań. Najlepiej dać tę pracę webmasterom, ponieważ cały czas pracują z dokumentem. Ponadto mogą wystąpić pewne zmiany w postrzeganiu dyrektyw przez wyszukiwarki. Jeśli masz małą witrynę - mały sklep internetowy lub blog - wystarczy, że przestudiujesz to pytanie i weźmiesz jeden z uniwersalnych przykładów.