Technologia OCR (Optical Character Recognition) może zostać wykorzystana do konwersji dokumentu papierowego na wersję elektroniczną. Na przykład, jeśli instancja wielostronicowa jest skanowana do pliku TIFF, jest ładowana do programu OCR, który rozpoznaje tekst, a następnie konwertuje go do pliku edytowalnego. Niektóre programy umożliwiają skanowanie stron i konwersję zawartości do dokumentu w jednym kroku. Chociaż technologia została pierwotnie opracowana do optycznego rozpoznawania znaków, może być również używana do odręcznych znaków. Na przykład usługi pocztowe, takie jak USPS, wykorzystują oprogramowanie OCR do automatycznego przetwarzania listów i paczek poprzez odczytanie adresu.
Obszary zastosowania OCR
OCR jest dekodowany jako optyczne rozpoznawanie znaków. Jest to szeroko rozpowszechniona technologia rozpoznawania tekstu wewnątrz obrazów jako zeskanowanych dokumentów i zdjęć. Technologia służy do konwersji praktycznie każdego rodzaju obrazu zawierającego tekst pisany, odręczny lub wydrukowany na dane tekstowe do odczytu maszynowego.
OCR stało się popularne na początku lat 90. XX wieku, gdy próbowano zdigitalizować materiał historyczny. Od tego czasu metoda uległa znacznej poprawie i obecnie zapewnia prawie doskonałą precyzję optycznego rozpoznawania znaków. Zaawansowane techniki, takie jak Zonal OCR, służą do automatyzacji złożonych przepływów pracy w oparciu okonwersję tekstów maszynowych na dokumenty cyfrowe. Po przetworzeniu zeskanowanego materiału tekst można edytować za pomocą programów takich jak Microsoft Word lub Dokumenty Google, które są edytorami tekstu. Zanim pojawiła się ta technologia, jedynym sposobem na digitalizację drukowanych dokumentów było ręczne wpisanie tekstu. To nie tylko zajęło dużo czasu, ale także doprowadziło do niedokładności i błędów w reprodukcji kopii. OCR jest często wykorzystywany jako "ukryta" technologia w wielu znanych systemach i usługach, które obejmują automatyzację wprowadzania i indeksowania danych dla wyszukiwarek, automatyczne optyczne rozpoznawanie znaków na tablicach rejestracyjnych, a także pomoc dla osób niewidomych i niedowidzących.
Proces określania dokładności tekstu
Każdy etap procesu OCR jest ważny dla określenia dokładności ostatecznego tekstu. Rozpoczyna się od konwersji drukowanego dokumentu. Jeśli ma ślady, plamy i słaby kontrast, oprogramowanie rozpoznaje błędy, a wynik okaże się niepoprawny. Aby uniknąć tych problemów, możesz poprawić kserokopię wydruku. Pierwszym etapem pracy jest zeskanowanie wydrukowanego tekstu. Oprogramowanie OCR współpracuje z plikami obrazów. Skaner lub dobry aparat cyfrowy tworzy wyraźne kserokopie dokumentów. Lepiej konwertować zeskanowane pliki w czerni i bieli. Proces jest binarny. Czarnym kolorem na zdjęciu rozpoznawanie tekstu OCR jest rozpoznawane, a białe z kolei działają jako tło. Drugi etap todefinicja postaci Szybkość tego procesu zależy od używanego programu OCR. Większość z nich analizuje każdy element jeden po drugim. Celem programu jest identyfikacja znaków, ale dobre programy rozpoznają nie tylko tekst, ale także tabele i inne elementy układu. Proces nie jest doskonały, ponieważ istnieje wiele czynników wpływających na dokładność. Jakie programy są przeznaczone do optycznego rozpoznawania znaków, rozważymy poniżej. Użytkownik może wybrać to, co najlepsze. OCR mają wbudowane funkcje sprawdzania pisowni i podkreślają wprowadzające w błąd słowa. Niektóre z nich są tak złożone, że oznaczają niedopasowanie słów i błędy gramatyczne, użytkownik musi tylko dokonać niezbędnych zmian. Ostatnim krokiem jest zapisanie gotowego dokumentu we właściwym formacie. Jeśli aplikacja nie czyni tego koniecznym, możesz skorzystać z wielu darmowych konwektorów online.
Technologia optyczna dla brajla
Technologia optycznego rozpoznawania znaków (OCR) daje osobom niewidomym lub niedowidzącym możliwość definiowania tekstu i wymawiania go na głos. Wykorzystuje to wyjście językowe i wyświetla informacje na monitorze brajlowskim. Istnieją trzy główne elementy optycznego systemu rozpoznawania znaków: pozyskiwanie obrazu, rozpoznawanie i odczytywanie tekstu. Po pierwsze, drukowany dokument jest przechwytywany przez kamerę, a następnie oprogramowanie OCR przekształca je w rozpoznawalne znaki i słowa, a następnie syntezator w systemie wypowiada na głos dowolny materiał lub wyświetla na monitorze brajlowskim. Informacje mogąprzechowywane elektronicznie na urządzeniu z uruchomionym oprogramowaniem OCR lub w wolnostojącej pamięci urządzenia. Proces uwzględnia logiczną strukturę języka. System wywnioskuje, że na przykład związek "ten" na początku wniosku jest błędem i powinien być czytany jako "ten". Korzysta ze słownika i stosuje metody weryfikacji, podobne do stosowanych w wielu edytorach tekstu. Wszystkie systemy OCR tworzą pliki tymczasowe zawierające znaki i układy stron. W niektórych systemach można je konwertować na formaty, które można znaleźć za pomocą powszechnie używanych aplikacji komputerowych, takich jak edytor tekstu, arkusz kalkulacyjny i bazy danych.
Wybór programów do rozpoznawania tekstu
Zaleca się, abyś świadomie podchodził do wyboru oprogramowania do rozpoznawania tekstu. Najlepiej przetestować siebie lub wziąć pod uwagę opinię zaawansowanych użytkowników. Testy są przeprowadzane z uwzględnieniem następujących czynników:
Dokładność jest tym, co odróżnia dobre OCR od złego. Jednak nierealistyczne jest oczekiwanie 100% dokładności programu rozpoznawania pisma ręcznego. Czynniki takie jak jakość oryginalnych dokumentów i rozdzielczość obrazu znacząco wpływają na końcowy rezultat. Dobre rozpoznawanie OCR osiąga 98% przy użyciu nowoczesnego skanera i kodu źródłowego w zadowalającym stanie.
Wielojęzyczność - obecnie ta funkcja jest własnością większości programów. OCR skanuje oddzielny znak, aby go zidentyfikować. Jeśli jest przeznaczony do rozpoznawania tylko angielskich liter, to nie będzie w stanieprecyzyjnie interpretować znaki specjalne, na przykład litery takie jak litery podkreślające "e". To będzie reprezentować te znaki z najbliższym odpowiednikiem w języku angielskim. Podczas stosowania aplikacji obsługującej wielojęzyczność, język dokumentu jest określony w celu zapewnienia dokładności rozpoznawania.
Wsparcie pisma ręcznego. Tekst utworzony za pomocą klawiatury jest łatwo rozpoznawany przez każdy program. Jednak odręcznie to zupełnie inna metoda skanowania. Ludzie mają bardzo różne pismo odręczne. Niektórzy piszą zgrabnie, a większość pisma nie jest dostatecznie czytelna. Jakościowe OCR mogą rozpoznawać każde pismo ręczne. Dlatego do archiwizowania odręcznego materiału potrzebne są programy do pisania pisma ręcznego.
Poziom automatyzacji. OCR można uruchomić automatycznie lub interaktywnie. Jeśli chcesz skanować wiele stron naraz, najlepiej wziąć pod uwagę automatyczne programy. Dzięki tej funkcji możesz skanować dokumenty kilkoma kliknięciami podczas wykonywania innych zadań i łatwo znaleźć wynikowy plik PDF, txt lub dokument. Większość darmowych programów do rozpoznawania tekstu ma ograniczoną automatyzację.
Zachowanie układu. Głównym celem tych programów jest tłumaczenie tekstu na formę elektroniczną. Niektóre nie zachowują układu oryginalnego dokumentu. Dlatego konieczna jest edycja ostatecznej wersji przez długi czas. Dobry program powinien zachować oryginalny układ, a kopia ostateczna jest wymagana. Takie programy przechowują kolumny tabel i obrazy graficzne, tak jak w wersji oryginalnej.
Popularne oprogramowanie mobilne
OCR świetnie nadaje się do przesyłania tekstu z fizycznych źródeł bezpośrednio do cyfrowego dokumentu. Istnieją różne typy aplikacji i aplikacji zarówno na komputery stacjonarne, jak i urządzenia mobilne. Są różne w cenie i mają swoje własne kluczowe doskonałe cechy.
Najpopularniejsze skanery Android:
Soczewki biurowe - Zapewnia bezpłatne skanowanie stron i OCR dla użytkowników Androida. Aby dokonać konwersji, musisz połączyć się z Internetem.
Skanery PDF (na przykład ABBYY TextGrabber, CamScanner, MDScan, OCR Natychmiast) - przeprowadzają skanowanie z późniejszym OCR. Nie ma ograniczeń dotyczących liczby zeskanowanych stron i znaków wodnych.
Online OCR. Można go znaleźć w Internecie, usługa jest bardzo prosta i łatwa w użyciu. Charakterystyczną cechą jest to, że obsługuje 46 języków, dokument wyjściowy waży nie więcej niż 5 MB, można go łatwo przekonwertować na format Microsoft Word, Excel lub zwykły tekst. Po rejestracji można przekonwertować wielostronicowy PDF, RTF, Excel i pliki do 100 MB. W przypadku dużych tomów uznania istnieje płatna wersja.
Dokumenty Google
Dla osób, które już znają dokumenty Google, możesz użyć OCR wbudowanego w Dysk Google. Aby uzyskać najlepsze wyniki, czcionka musi być ustawiona na Arial lub Times New Roman. Możesz poprawić wynik, upewniając się, że zeskanowany obraz ma nawet jasny i wyraźny kontrast. Materiały fotograficzne można przetwarzać pojedynczo w formacie jpg, png, gif lub w wielostronicowych dokumentach PDF. Rozszerzenie obsługuje większość języków. Google ma wiele programów szkoleniowych i możliwości przetwarzania w chmurze. Wielu użytkowników uważa, że usługa nie ma zaawansowanych funkcji i opcji. Jeśli jednak korzystasz z aplikacji Dysk Google na Androida, możesz skanować strony bezpośrednio z aplikacji, korzystając z aparatu w smartfonie. W przeciwnym razie pobierz dokumenty za pomocą skanera podłączonego do komputera lub w inny sposób, aby rozpocząć przetwarzanie rozpoznawania na Dysku Google. W przypadku osób indywidualnych Dysk Google oferuje bezpłatny poziom pamięci masowej wynoszący około 19 GB z możliwością rozszerzenia do 100 GB za pośrednictwem Google One za 199 USD. USA
Rozpoznanie optyczne Abbyy'ego
Abbyy FineReader pracował z dokumentami przez długi czas. Jest to kompleksowe rozwiązanie zarówno dla użytkowników biznesowych, jak i zwykłych. Pozwala uzyskać wszystkie niezbędne funkcje do wydobywania treści tekstów z pełnowymiarowego czytnika, starannie uporządkowanych, zdigitalizowanych materiałów. Oprócz rozpoznawania tekstu i konwersji do formatu PDF, Microsoft Office lub innych formatów program może również je porównywać, dodawać adnotacje i komentarze. Abbyy FineReader może konwertować materiały w trybie wsadowym i obsługiwać wiele formatów wyjściowych w 192 różnych językach. Istnieją towarzyszące aplikacje mobilne, gdy musisz wykonać szybkie skanowanie z telefonu. Oprogramowanie nie jest aktualne, ale jest proste, funkcjonalne i dobrze współpracuje z jego pracą. Narzędzie ma solidną reputację jako jedna z najlepszych opcji w dziedzinie optycznego rozpoznawania znaków. Możesz skorzystać z bezpłatnej wersji próbnej. ZA Koszt od19999 dolarów USA na standardową pojedynczą licencję wieczystą. Jeśli ktoś wydaje się być drogą opcją, możesz wybrać dobrą alternatywę dla ABBYY FineReader - wersji online. Ogranicza się do skanowania tylko 10 stron miesięcznie. Ale jest wyposażony we wszystkie inne funkcje premium. Aby uzyskać dostęp, musisz się zarejestrować. Obsługuje wiele formatów plików wejściowych i można wybrać pliki wyjściowe, takie jak PDF, Word, Excel, PowerPoint i e-Pub.
Usługa Cloud Acrobat
Adobe Acrobat spełnia wszystkie wymagania i oferuje imponującą listę funkcji i opcji, chociaż cena jest nieco bardziej stroma niż konkurencja. W przypadku wszystkich funkcji optycznego rozpoznawania tekstu wybierz wersję Pro programu Adobe Acrobat. DC to skrót od "Document Cloud" i całkiem dobrze integruje się z rozwiązaniem chmurowym Adobe, jeśli chcesz uzyskać dostęp do plików z dowolnego komputera. Istnieje również prosta i bezproblemowa integracja ze wszystkimi innymi usługami Adobe, takimi jak Photoshop. Jeśli użytkownik zdecyduje się zapłacić za wersję Pro programu Adobe Acrobat DC, otrzyma wszystkie narzędzia do rozpoznawania tekstu, możliwość dodawania komentarzy i opinii do treści, specjalistyczną usługę do skanowania tabel, możliwość szybkiego porównania dwóch dokumentów razem. Materiały można edytować bezpośrednio na ekranie kilka sekund po zeskanowaniu. Logo Adobe gwarantuje pewien poziom jakości, a użytkownicy są pod wrażeniem intuicji i możliwości Adobe Acrobat DC. Subskrypcja usługi zaczyna się od 1,299 USD. USA
Najlepsze darmowe oprogramowanie
Bezpłatne OCR to Word to najlepsze darmowe oprogramowanieOptyczne oprogramowanie do rozpoznawania znaków za pomocą najnowszych mechanizmów. Tesseract jest najpotężniejszym narzędziem tego typu i jest uważany za jedną z najdokładniejszych metod. Program obsługuje wiele formatów obrazu i TIFF wielu stron. Ta usługa może być całkowicie bezpłatna w celu wyodrębnienia tekstu z dostarczonego materiału fotograficznego. Silnik Tesseract został pierwotnie opracowany przez Hewlett Packard Labs w latach 1985-1994. W 1996 r. Dokonano pewnych zmian. W 1995 roku znalazł się w pierwszej trójce mechanizmów rozpoznawania. Działa z systemami Windows, Linux i Mac OS X. FreeOCR może obsługiwać obrazy z tekstem wielojęzycznym i wielojęzycznym. Obsługuje formaty PDF i obsługuje urządzenia TWAIN, takie jak skanery, ma szeroki, podwójny interfejs, który jest łatwy do zrozumienia.
Bezpłatne OCR do Worda pozwala zaoszczędzić sporo czasu bez konieczności ponownego wpisywania utworu już napisanego. Program pobiera dokument, zeskanowany obiekt lub obraz i przekształca go w czytelny, edytowalny i dokładny materiał. Możesz pobrać go za darmo w programie Word. OCR to Word jest zoptymalizowany do pracy ze wszystkimi typami skanerów i ma dokładność 98%, nowoczesny interfejs, który ułatwia dostęp do wszystkich zadań, są funkcje rotacji na wypadek, gdyby zdjęcie nie pasowało poprawnie na ekranie. FOR wyciąga tekst z przechwyconych obrazów za pomocą smartfonów lub aparatów cyfrowych o wysokiej dokładności i jakości.
Rozpoznawanie znaków w systemie Linux
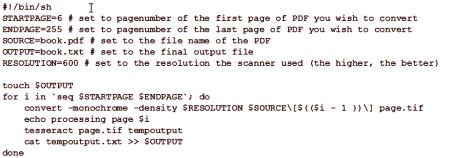
Pakiet OCRFeeder zapewnia wygodny graficzny interfejs użytkownika dla systemu Linux.który jest w zasadzie zewnętrznym interfejsem niektórych obrazów, OCR i narzędzi tekstowych, takich jak sprawdzanie pisowni lub pisowni. Sam nie czyta znaków, ale używa innych programów OCR poprzez tak zwane ustawienia "mechanizmów rozpoznawania". Ma pewne parametry dla Tesseract, CuneiForm, GOCR i Ocrad. Użytkownik musi tylko zainstalować w systemie Ubuntu silniki, które wybierze - jedną lub więcej, a następnie wykryć je w ustawieniach podajnika. Możesz dodać inne silniki i ręcznie zmodyfikować te ustawienia. W jednej aplikacji może być kilka różnych silników. Główne okno Feeder pozwala wybrać w locie, który z nich ma być używany dla konkretnej branży, istnieje również domyślne ustawienie. Aby wybrać język czytać tekst, w przypadku Tesseract i klinowych, należy dodać przełącznik «-l» Z odpowiedni język /kod skryptu, na przykład, «-l pol» na polski lub «-l dan-frak» duńskich ustawieniach silnika Technologia optycznego rozpoznawania drukowanych znaków "Tesseract" na początku potrafiła rozpoznać tekst w języku angielskim, wersja 2.x uczyniła go wielojęzycznym. Jeśli to konieczne, możesz zainstalować więcej niż jeden słownik. Nowe wersje digitalizują tekst na podstawie ISO 963-2. Po udanej instalacji użyj polecenia "tesseract & gt; ścieżka do obrazu & gt; nazwa podstawowa pliku wyjściowego". Tesseract automatycznie dodaje plik źródłowy rozszerzenia .txt, można podać opcję -l, po której następuje kod języka. W przypadku wersji Tesseract wcześniejszych niż trzecia bardzo ważne jest, aby obraz był trochę w formacie pliku znacznikówrozszerzenie ".tif", a nie ".tiff". Wiersz poleceń powinien wyglądać tak: "$ tesseract ~ /input.tif output". Gdzie "input.tif" jest dokumentem transformacji znajdującym się w katalogu domowym, a "output" to materiał, który Tesseract utworzy jako "output.txt". Często skanowane teksty są zapisywane jako obraz rastrowy w dużym dokumencie PDF. Korzystając z ImageMagick, poszczególne strony można wyodrębnić jako pliki TIFF do przetwarzania z Tesseract. Poniższy skrypt może pomóc zautomatyzować ten proces.
Program CuneiForm to kolejny optyczny system rozpoznawania tekstu, który został pierwotnie opracowany i oparty na Open Source Cognitive Technologies. Wersja Windows z własnym interfejsem graficznym może być uruchomiona z pewnymi wynikami w Wine. Port Linux jest rozwijany na Launchpad i chociaż obecnie nie ma własnego interfejsu graficznego, można z powodzeniem uruchomić CuneiForm z interfejsu graficznego OCRFeeder. Poniżej znajduje się przykład, w jaki sposób z powodzeniem konwertować niektóre zrzuty ekranu z biuletynów graficznych .jpeg na użyteczne pliki tekstowe online.
Pdfocr to skrypt, który wykonuje OCR dla wielostronicowych plików PDF, a także implementuje go jako możliwą do wyszukania warstwę tekstową. Potrafi użyć Tesseract lub klinowego jako mechanizmu rozpoznawania. Sam skrypt można uzyskać z Github lub PPA. Aby uruchomić polecenie, napisz w terminalu: "pdfocr -i input.pdf -o output.pdf". Technologia OCR nie stoi w miejscu, w perspektywie długoterminowej rozpoznaje intelektualny system optycznego rozpoznawania znaków - ICR. Ten standard jest zaawansowany. Świetnieczęść ICR ma system samouczenia się zwany siecią neuronową, który automatycznie aktualizuje bazę danych w poszukiwaniu nowych wzorów pisma ręcznego. Rozszerza przydatność urządzeń skanujących do celów przetwarzania dokumentów od rozpoznawania tekstu drukowanego (funkcja OCR) do materiałów pisanych odręcznie i może osiągnąć ponad 97% dokładność podczas odczytywania odręcznego materiału w postaciach strukturalnych.