Zgodnie z Międzynarodowego Związku Telekomunikacyjnego, w 2016 roku Internet z różnym prawidłowości cieszył trzy i pół miliarda ludzi. Większość z nich nawet nie myśleć, że wszelkie wiadomości, które odwołują się je za pośrednictwem komputera lub mobilnych gadżetów i tekstu wyświetlanego na różnych monitorach faktycznie są kombinacją 0 i 1. To przekazywanie informacji jest nazywany kodowanie. Zapewnia i znacznie ułatwia przechowywanie, przetwarzanie i przesyłanie. W 1963 roku opracowano amerykański kodek ASCII, który poświęcony jest również temu artykułowi.
Przedstawienie informacji w komputerze
Pod względem dowolnego elektronicznego komputera tekst jest zbiorem pojedynczych znaków. Obejmują one nie tylko litery, w tym duże, ale także znaki interpunkcyjne, liczby. . Ponadto, znaki specjalne «=», «& amp;», «(» i luki Wiele znaków składających się na tekst, zwany alfabet i ich numery - zasilanie (oznaczone jako n) w przypadku jego definicji wyrażenie N. = 2 ^ b, gdzie b. -. liczbę bitów lub masy informacyjnego danego znaku zostanie udowodnione, że zdolność alfabet 256 znaków może zapewnić wszystkich tych znaków, od 256 to 8 stopni dwa, waga każdego znaku jest 8 bitów jednostka 8 bitów. jest nazywane 1 bajtem, więc często można powiedzieć, że kod binarny dowolny znak w zapisanym tekściekomputer, bierze jeden bajt pamięci.
W jaki sposób kodowania
Każdy tekst wpisany w pamięci komputera osobistego za pomocą klawiatury, na którym zostały napisane cyfry, litery, znaki interpunkcyjne i inne znaki. W pamięci są przesyłane w postaci kodu binarnego, każdy znak w stosunku do normalnej ludzkiej desyaterychnыy kodu od 0 do 255, co odpowiada binarnego kodu 00000000 do 11111111.
kodowanie Pobaytovoe umożliwia procesor, który wykonuje przetwarzanie tekstu, odnoszą się do każdej postaci osobno. W tym samym czasie 256 znaków wystarcza, aby reprezentować dowolne informacje symboliczne.
kodowanie znaków ASCII
Ten skrót oznacza angielskim jako American Standard Code dla wymiany informacji. U zarania komputeryzacji było oczywiste, że można myśleć o różnych sposobów kodowania informacji. Jednak przekazywanie informacji z jednego komputera do drugiego było stworzenie jednolitego standardu. Tak więc w 1963 roku pojawił się w Stanach Zjednoczonych stół do kodowania ASCII. To dowolny komputer charakter alfabet dostarczone zgodnie z jego numerem seryjnym w reprezentacji binarnej. Początkowo kodowanie ASCII było używane tylko w Stanach Zjednoczonych, a następnie stało się międzynarodowym standardem dla komputerów PC.
Spis treści
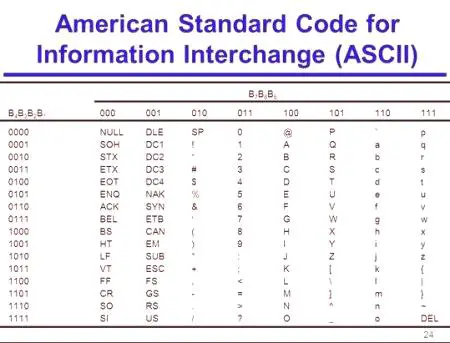
Kody ASCII są podzielone na 2 części. Międzynarodowy standard uznaje się tylko za pierwszą połowę tej tabeli. Zawiera znaki o numerach sekwencji od 0 (zakodowanych jako 00000000) do 127 (kod 01111111).
Numer porządkowy N
Kodowanie tekstu ASCII
Symbol
0 - 31
00000000 - 00011111
Symbole od N od 0 do 31 nazywane są kontrolerami. Ich funkcją jest prowadzenie procesu produkcji tekstowego monitora lub drukarki składającej dźwiękowego i tak dalej N.
32 -. 127
00100000 - 01111111
znaków z N od 32 do 127 (standardowe części tabeli) - wielkie litery i małe litery alfabetu łacińskiego, 10-a cyfry, znaki interpunkcyjne i wsporników handlowe i inne. postacie Symbol 32 jest oznaczony spacją.
, 128 - 255
10000000 - 11111111
znaków o Mn od 128 do 255 (alternatywą tabel lub strony kodowej) mogą mieć różne wersje, każda z własnym numerem. Strona kodowa służy do oznaczania alfabetów narodowych innych niż łaciński. W szczególności wykorzystuje kodowanie ASCII dla rosyjskich znaków.
Kodowanie Tabela wielkie litery i małe są jeden po drugim w porządku alfabetycznym wartości liczbowych - wznoszący. Ta zasada obowiązuje dla alfabetu rosyjskiego.
Zdjęcia sterowania
Tabela kodowania ASCII utworzony do przyjmowania i przekazywania takich informacji nie jest już używana przez urządzenie jako dalekopisów. W związku z tym, zestaw znaków zawarte niezadrukowana używane jako polecenia do sterowania tego urządzenia. Podobne polecenia stosowane w takich sposobach dokompyuternыh wiadomości jak Morse i inni
najczęściej „teletaypnыm”symbolem jest NUL (00 "zero"). Nadal jest używany w większości języków programowania, oznaczając koniec linii.
Gdzie stosować kodowanie ASCII
Amerykański standardowy kod jest wymagany nie tylko do wprowadzania informacji tekstowych za pomocą klawiatury. Jest również używany na wykresie. W szczególności w programie ASCII Art Maker obraz różnych rozszerzeń jest spektrum kodowania znaków ASCII. Podobne produkty mogą być dwojakiego rodzaju: wykonują funkcję edytorów graficznych, konwertując obraz na tekst i konwertując "rysunki" na wykres ASCII. Na przykład dobrze znana buźka jest żywym przykładem kodującej postaci.
ASCII może być również używany podczas tworzenia dokumentu HTML. W takim przypadku możesz wprowadzić określony zestaw znaków, a gdy spojrzysz na stronę, pojawi się symbol odpowiadający temu kodowi. ASCII jest również wymagany do tworzenia witryn wielojęzycznych, ponieważ znaki, które nie są częścią określonej tabeli krajowej, są zastępowane kodami ASCII.
Niektóre funkcje
Do kodowania informacji tekstowych w kodowaniu ASCII, początkowo użyto 7 bitów (jeden pozostał pusty), ale dziś działa jak 8-bitowy. Litery, znajdujące się w kolumnach znajdujących się na górze i na dole, różnią się od siebie tylko bitem tylko jednym. To znacznie zmniejsza złożoność testu.
Użycie Microsoft Office ASCII
W razie potrzeby ten rodzaj kodowania informacji tekstowych może być używany przez procesory Microsoft, takie jak Notatnik i Office Word.Jednak przy wpisywaniu tekstu w tym przypadku niemożliwe będzie użycie niektórych opcji. Na przykład nie można przydzielić pogrubienia, ponieważ kodowanie ASCII zachowuje tylko zawartość informacji, ignorując jej ogólny wygląd i formę.
Normalizacja
ISO przyjęło normy ISO 8859. Ta grupa definiuje osiemznakowe kodowanie dla różnych grup językowych. W szczególności ISO 8859-1 - Rozszerzony ASCII jest tabelą dla Stanów Zjednoczonych i krajów Europy Zachodniej. I ISO 8859-5 jest tabelą używaną dla cyrylicy, w tym dla języka rosyjskiego. Z kilku powodów historycznych ISO 8859-5 był używany przez bardzo krótki czas. W przypadku języka rosyjskiego kodowanie jest aktualnie używane:
CP866 (Code Page 866) lub DOS, który jest często nazywany alternatywnym kodowaniem GOST. Był aktywnie używany do połowy lat 90-tych ubiegłego wieku. Obecnie praktycznie nie używane. KOI-8. Kodowanie zostało opracowane w latach siedemdziesiątych i osiemdziesiątych, a obecnie jest standardowym standardem dla wiadomości pocztowych w RuNet. Jest szeroko stosowany w systemach operacyjnych Unix, w tym Linux. "Rosyjska" wersja KOI-8 nosi nazwę KOI-8R. Ponadto istnieją wersje dla innych języków cyrylicą, na przykład ukraiński. Kod Page 1251 (CP 1251 Windows-1251). Zaprojektowany przez firmę Microsoft do obsługi języka rosyjskiego w środowisku Windows.Główną zaletą pierwszego standardowego CP866 było zachowanie znaków pseudograficznych na tych samych pozycjach, co w rozszerzonym ASCII. Pozwalało działać bez zmianaplikacje tekstowe, za granicą, takie jak słynny Norton Commander. Obecnie CP866 jest używany do programów opracowanych pod Windows działających w trybie pełnoekranowym lub w polach tekstowych, w tym FAR Manager. Teksty komputerowe napisane w szyfrowaniu CP866 były rzadko spotykane w ostatnim czasie, ale właśnie to jest używane w rosyjskich nazwach plików w Vindous.
Unicode
Obecnie najczęściej jest to kodowanie. Kody Unicode są podzielone na obszary. Pierwsza (od U + 0000 do U + 007F) zawiera znaki ASCII z kodami. Następnie są obszary znaków różnych narodowości, a także znaki interpunkcyjne i symbole techniczne. Ponadto niektóre kody Unicode są zarezerwowane w przypadku konieczności dołączania nowych symboli w przyszłości.
Teraz wiesz, że w kodowaniu ASCII każdy znak jest reprezentowany jako kombinacja 8 zer i jednostek. Dla osób niebędących specjalistami ta informacja może wydawać się niepotrzebna i nieinteresująca, ale czy nie chcesz wiedzieć, co dzieje się "w mózgu" komputera?