Bufor pierścieniowy jest również znany jako kolejka lub bufor cykliczny i jest powszechną postacią kolejki. Jest to popularny, łatwo zaimplementowany standard i chociaż jest reprezentowany jako okrąg, jest on liniowy w kodzie podstawowym. Kolejka pierścieniowa istnieje jako tablica stałych długości z dwoma wskaźnikami: jeden reprezentuje początek kolejki, a drugi - ogon. Wadą tej metody jest jej stały rozmiar. W przypadku kolejek, w których elementy muszą być dodawane lub usuwane w środku, a nie tylko na początku i końcu bufora, najlepszym rozwiązaniem jest implementacja jako lista połączona.
Podstawy teoretyczne bufora
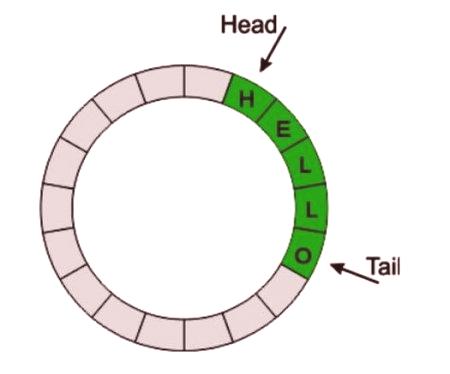
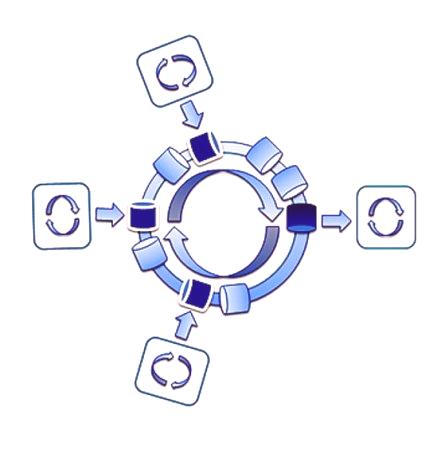
Łatwiej jest użytkownikowi wybrać skuteczną strukturę macierzy po zrozumieniu podstawowej teorii. Bufor cykliczny to struktura danych, w której tablica jest przetwarzana i wizualizowana w postaci pętli, to znaczy indeksy powracają do 0 po osiągnięciu długości tablicy. Odbywa się to za pomocą dwóch wskaźników w tablicy: "głowa" i "ogon". Gdy dane zostaną dodane do bufora, indeks nagłówków przesunie się w górę. Podobnie, kiedy są usuwane, ogon porusza się również w górę. Definicja głowy, ogona, kierunku ruchu, miejsca rejestracji i czytania zależy od realizacji programu.
Bufory kołowe są nadmiernie efektywnie wykorzystywane do rozwiązywania problemów konsumenckich. Oznacza to, że jeden przepływ wykonania odpowiada za produkcję danych, a drugi za zużycie. W urządzeniach wbudowanych o bardzo niskim i średnim poziomie producent jest prezentowany w formacie ISR (informacje otrzymywane z czujników), a konsument - w formiegłówny cykl zdarzeń. Cechą cyklicznych buforów jest to, że są one realizowane bez potrzeby blokowania w środowisku jednego producenta i jednego konsumenta. To czyni je idealną strukturą informacji dla aplikacji wbudowanych. Kolejna różnica polega na tym, że nie ma dokładnego sposobu odróżnienia wypełnionego sektora od pustego. Dzieje się tak, ponieważ w obu przypadkach głowa łączy się z ogonem. Jest wiele sposobów i sposobów radzenia sobie z nim, aby poradzić sobie z tym, ale większość z nich sprawia, że jest bardziej zagmatwany i komplikuje czytelność.
Kolejna kwestia, która powstaje w związku z buforem cyklicznym. Chcesz zresetować nowe dane lub ponownie nagrać istniejące, gdy są pełne? Specjaliści twierdzą, że nie ma oczywistej przewagi nad sobą, a jej realizacja zależy od konkretnej sytuacji. Jeśli te ostatnie są bardziej odpowiednie dla aplikacji, użyj metody przepisywania. Z drugiej strony, jeśli są przetwarzane w trybie "kto pierwszy ten lepszy", to odrzucają nowe, gdy bufor pierścieniowy jest wypełniony.
Realizacja cyklicznej kolejki
Jeśli chodzi o implementację, definiuje się typy danych, a następnie metody: core, push i pop. W procedurach "popchnij" i "pop" obliczyć "takie" punkty zmiany miejsca, w którym odbędzie się bieżące nagranie i odczyt. Jeśli ta lokalizacja wskazuje na ogon, bufor jest pełny i dane nie są rejestrowane. Podobnie, gdy "head" jest równy "tail", jest puste i nic nie jest odczytywane z niego.
Standardowa wersja użycia
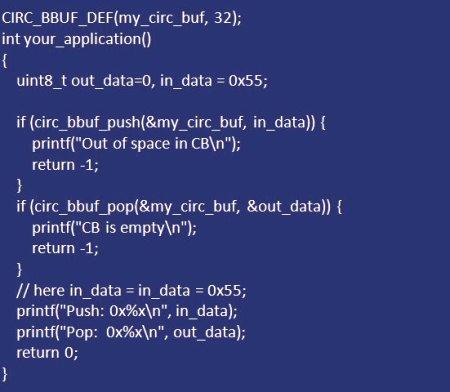
Procedura pomocnicza jest wywoływana w procesie programuwyodrębnić dane z okrągłego bufora Java. Powinien być zawarty w sekcjach krytycznych, jeśli kontener czyta więcej niż jeden wątek. Ogon przesuwa się do następnej zmiany przed odczytaniem informacji, ponieważ każdy blok jest jeden bajt i rezerwuje taką samą ilość w buforze, gdy objętość jest w pełni załadowana. Ale w bardziej zaawansowanych implementacjach napędu cyklicznego oddzielne sekcje niekoniecznie muszą być tego samego rozmiaru. W takich przypadkach próbują zapisać nawet ostatni bajt, dodając więcej czeków i granic. W takich schematach, jeśli ogon porusza się przed odczytem, informacje, które powinny zostać odczytane, mogą potencjalnie zostać nadpisane przez nowo przesłane dane. Ogólnie zaleca się najpierw przeczytać, a następnie przesunąć wskaźnik ogonowy. Najpierw określ długość bufora, a następnie utwórz instancję "circ_bbuf_t" i przypisz wskaźnik do "maxlen". W takim przypadku kontener musi być globalny lub ułożony w stos. Na przykład, jeśli potrzebujesz 32-bajtowego bufora pierścieniowego, wykonaj poniższe czynności w załączniku (patrz rysunek poniżej).
Specyfikacja wymagań funkcjonalnych
Typ danych "ring_t" będzie rodzajem danych zawierających wskaźnik do bufora, jego wielkością, indeksem nagłówka i ogona oraz licznikiem danych. Funkcja inicjalizacji "ring_init ()" inicjuje bufor na podstawie uzyskania wskaźnika do struktury kontenera utworzonego przez funkcję wywołania o określonym rozmiarze. Funkcja ring_add () dodaje bajt do następnego dostępnego miejsca w buforze.Funkcja usuwania ring_remove () usunie bajt z najstarszego dostępnego miejsca w kontenerze. Podgląd pierścienia w funkcji ring_peek () odczyta liczbę bajtów "uint8_t 'count" z bufora pierścieniowego do nowego, podaną jako parametr, bez usuwania jakichkolwiek wartości z kontenera. Zwróci liczbę faktycznie odczytanych bajtów. Funkcja ring_clear () ustawi "Tail" równy "Head" i załaduje "0" we wszystkich pozycjach bufora.
Tworzenie bufora w C /C ++
Ze względu na ograniczone zasoby wbudowanych systemów, struktura danych z buforem cyklicznym znajduje się w większości projektów o stałym rozmiarze, które działają tak, jakby pamięć z natury była ciągła i cykliczny Nie trzeba zmieniać rozkładu danych, ponieważ pamięć jest generowana i używana, a wskaźniki head /tail są poprawione. Podczas tworzenia cyklicznej biblioteki buforowej użytkownicy muszą pracować z bibliotekami API, a nie bezpośrednio zmieniać strukturę. Dlatego stosuje się enkapsulację bufora pierścieniowego na "C". W ten sposób programista zapisze implementację biblioteki, zmieniając ją w razie potrzeby, bez konieczności aktualizacji jej przez użytkowników końcowych.
Użytkownicy nie mogą pracować ze wskaźnikiem "circular_but_t", tworząc typ deskryptora, który może być użyty zamiast tego. Eliminuje to konieczność przesuwania kursora, aby zaimplementować funkcję .typedefcbuf_handle_t. Programiści muszą tworzyć interfejsy API dla biblioteki. Oddziałują z biblioteką kolistego bufora "C", używając nieprzejrzystego typu deskryptora,który jest tworzony podczas inicjalizacji. Zwykle wybierz "uint8_t" jako podstawowy typ danych. Ale możesz użyć dowolnego określonego typu, dbając o prawidłowe obsłużenie bufora bazowego i liczby bajtów. Użytkownicy wchodzą w interakcję z kontenerem, wykonując wymagane procedury:
Inicjalizuj kontener i jego rozmiar.
Zresetuj okrągły pojemnik.
Dodaj dane do bufora pierścieniowego w "C".
Uzyskaj z pojemnika następującą wartość.
Proszę uzyskać informacje na temat bieżącej liczby pozycji i maksymalnej zdolności przesyłowej.
A "pełne" i "puste" przypadki wyglądają tak samo: "głowa" i "ogon", wskaźniki są równe. Istnieją dwa podejścia, które rozróżniają pełne i puste:
Kompletny ogon stanu + 1 == głowa.
Pusta głowica stanu == ogon.
Implementacja funkcji bibliotecznych
Aby utworzyć okrągły kontener, użyj jego struktury do sterowania stanem. Aby zapisać enkapsulację, struktura jest zdefiniowana w pliku biblioteki .c, a nie w nagłówku. Podczas instalacji należy śledzić:
Podstawowy bufor danych.
Maksymalny rozmiar.
Aktualna pozycja głowy zwiększa się wraz z dodatkiem.
Obecny ogon, zwiększa się po usunięciu.
Flaga wskazująca napełniony pojemnik lub nie.
Po zaprojektowaniu kontenera implementuje funkcje biblioteczne. Każdy interfejs API wymaga inicjalizowanego deskryptora bufora. Zamiast zatkania kodu za pomocą instrukcji warunkowych, należy wystąpić o zatwierdzenie w celu egzekwowania wymagańAPI w dobrym stylu.
Implementacja nie będzie zorientowana na prąd, jeśli do biblioteki bazowej cyklicznych repozytoriów nie zostanie dodana żadna blokada. W celu inicjalizacji interfejsu API klienci, którzy dostarczają podstawowy rozmiar bufora, tworzą go po stronie biblioteki, na przykład w celu uproszczenia "malloc". Systemy, które nie mogą korzystać z pamięci dynamicznej, powinny zmienić funkcję "init", aby użyć innej metody, na przykład wybierając statyczną pulę kontenerów. Innym podejściem jest przełamanie enkapsulacji, pozwalając użytkownikom statycznie zadeklarować struktury kontenerów. W takim przypadku "circular_buf_init" musi zostać zaktualizowane, aby otrzymać wskaźnik lub "init", utworzyć strukturę stosu i zwrócić ją. Jednak ponieważ enkapsulacja jest zakłócona, użytkownicy mogą modyfikować ją bez procedur bibliotecznych. Po utworzeniu kontenera wpisz jego wartość i wywołaj "reset". Przed powrotem z "init" system zapewnia, że kontener jest pusty.
Dodawanie i usuwanie danych
Dodawanie i usuwanie danych z bufora wymaga manipulowania wskaźnikami "głowa" i "ogon". Po dodaniu do kontenera wstaw nową wartość do bieżących "nagłówków" i promuj ją. Po usunięciu otrzymują wartość aktualnego "ogona" -indykatora i promują "ogon". Jeśli chcesz przenieść indeks "ogona", a także "głowę", musisz sprawdzić, czy wstawienie powoduje wartość "pełna". Kiedy bufor jest już pełny, przesuń "ogon" o krok do przodu "głową".
Po wprowadzeniu wskaźnika, wypełnij "pełne" - publikowanie,sprawdzanie równości "head == tail". Modułowe użycie operatora spowoduje, że "głowa" i "ogon" zresetują się do "0" po osiągnięciu maksymalnego rozmiaru. Dzięki temu "głowa" i "ogon" zawsze będą prawidłowymi bazami danych podstawowego kontenera danych: "static void advance_pointer (cbuf_handle_t cbuf)". Można utworzyć podobną funkcję pomocniczą, która jest wywoływana podczas usuwania wartości z bufora.
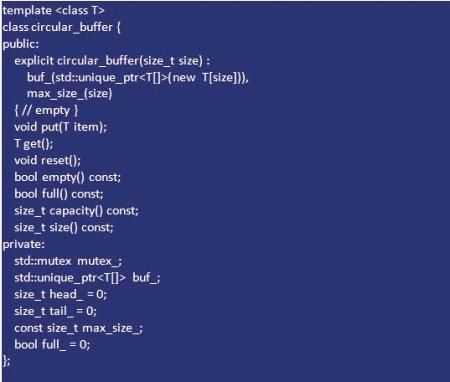
Interfejs szablonu
Aby implementacja C ++ obsługiwała dowolny typ danych, postępuj zgodnie z szablonem:
Zresetuj bufor do czyszczenia.
Dodawanie i usuwanie danych.
Sprawdzanie stanu pełnego /pustego.
Sprawdzanie aktualnej liczby pozycji.
Sprawdzanie całkowitej pojemności kontenera.
Aby nie pozostawiać żadnych danych po zniszczeniu bufora, inteligentne wskaźniki C ++ są używane w celu zapewnienia, że użytkownicy mogą zarządzać danymi.
W tym przykładzie bufor C ++ symuluje większość logiki implementacji C, ale powoduje znacznie czystszy i bardziej powtarzalny projekt. Ponadto kontener C ++ używa "std :: mutex", aby zapewnić implementację zorientowaną na prąd. Podczas tworzenia klasy wybierz dane dla głównego bufora i ustaw jego rozmiar. Eliminuje to narzut związany z implementacją C. W przeciwieństwie do niego konstruktor C ++ nie powoduje "zresetowania", ponieważ określa początkowe wartości elementów członkowskich, okrągły kontener działa w prawidłowym stanie. Funkcja resetowania przywraca bufor do pustego stanu. W implementacji cyklicznego kontenera C ++ "size" i"Pojemność" zgłasza liczbę elementów w kolejce, a nie rozmiar w bajtach.
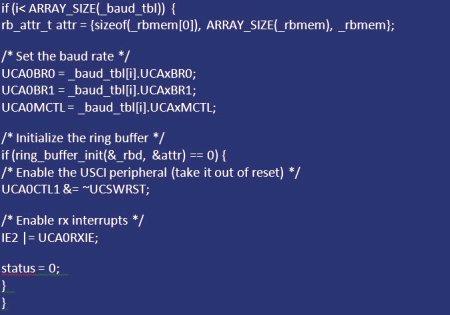
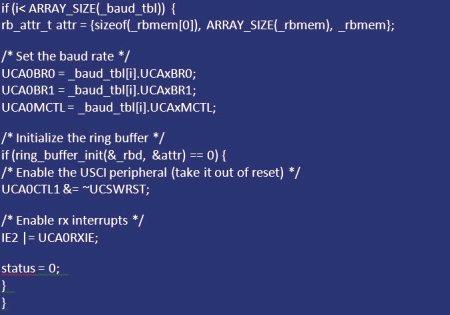
Sterownik UART STM32
Po uruchomieniu bufora należy go zintegrować ze sterownikiem UART. Po pierwsze jako globalny element w pliku, dlatego konieczne jest zadeklarowanie:
"descriptor_rbd" i pamięci buforowej "_rbmem: static rbd_t _rbd";
"static char _rbmem ".
Ponieważ jest to sterownik UART, gdzie każdy znak musi być 8-bitowy, tworzenie tablicy znaków jest dopuszczalne. Jeśli używany jest tryb 9 lub 10-bitowy, wówczas każdy element powinien mieć wartość "uint16_t". Kontener jest obliczany w taki sposób, aby uniknąć utraty danych. Często moduły kolejkowe zawierają informacje statystyczne, które umożliwiają śledzenie maksymalnego wykorzystania. W funkcji inicjalizacji "uart_init" bufor musi zostać zainicjalizowany przez wywołanie "ring_buffer_init" i przeniesienie struktury atrybutu do każdego członka, do którego przypisane są negocjowane wartości. Jeśli zostanie pomyślnie zainicjalizowany, moduł UART jest wyprowadzany z resetowania, odbiór przerwań jest dozwolony w IFG2.
Drugą funkcją, którą należy zmienić, jest "uart_getchar". Odczyt odebranego znaku z urządzenia peryferyjnego UART zastępuje się odczytem z kolejki. Jeśli kolejka jest pusta, funkcja musi zwrócić -1. Następnie musisz zaimplementować UART, aby uzyskać ISR. Otwórz plik nagłówka "msp430g2553.h", przewiń w dół do sekcji wektorów przerwań, gdzie znajduje się wektor o nazwie USCIAB0RX. Naming oznacza, że jest używany przez moduły USCI A0 i B0. Status przerwania odbioru USCI A0 można odczytać z IFG2. Jeśli jest zainstalowany, flaga powinna zostać wyczyszczona, a dane w komorze odbiorczej umieszczone w buforzeużywając "ring_buffer_put".
UART Data Store
To repozytorium dostarcza informacji o tym, jak odczytać dane UART za pomocą DMA, gdy nieznana jest liczba bajtów do odbioru z góry. Rodzina buforów kołowych STM32 może działać w różnych trybach:
Tryb odpytywania (bez DMA, bez IRQ) - aplikacja powinna testować bity statusu, aby sprawdzić, czy nowa postać została zaakceptowana i odczytać ją wystarczająco szybko, aby uzyskać wszystkie bajty. Bardzo prosta implementacja, ale nikt nie używa jej w prawdziwym życiu. Wady - łatwo przegapić odebrane znaki w pakietach danych, działa tylko dla niskich prędkości transmisji.
Tryb przerwań (bez DMA) - bufor pierścieniowy UART przerywa przerwanie, a CPU przechodzi do programu serwisowego w celu przetworzenia odbioru danych. Najbardziej rozpowszechnione podejście we wszystkich dzisiejszych aplikacjach działa dobrze w zakresie średnich zakresów. Minusy - procedura przetwarzania przerwania jest wykonywana dla każdego otrzymanego znaku, może zatrzymać inne zadania w wysokowydajnych mikrokontrolerach z dużą liczbą przerwań i jednocześnie systemem operacyjnym podczas odbierania pakietu danych.
Tryb DMA służy do przesyłania danych z rejestru USART RX do pamięci na poziomie sprzętu. Na tym etapie interakcja z aplikacją nie jest wymagana, z wyjątkiem konieczności przetwarzania danych otrzymanych przez aplikację. Praca z systemami operacyjnymi może być bardzo łatwa. Zoptymalizowany pod kątem wysokich szybkości przesyłania danych & gt; 1 Mbps i aplikacje o małej mocy, w przypadku dużych pakietów danych, zwiększenie rozmiaru bufora może się poprawićfunkcjonalność.
Implementacja ARDUINO
Arduino Ribbon Buffer odnosi się zarówno do projektowania desek, jak i do środowiska programistycznego. Rdzeniem Arduino jest mikrokontroler serii AVR firmy Atmel. Jest to AVR, który wykonuje większość pracy, i pod wieloma względami płyta Arduino wokół AVR zapewnia funkcjonalność - łatwo wtykowe kontakty, interfejs szeregowy USB do programowania i komunikacji. Wiele standardowych kart Arduino używa obecnie bufora pierścieniowego ze starszymi płytami ATmega 328, używanymi w ATmega168 i ATmega8. Tablice takie jak Mega wybierają bardziej złożone opcje, takie jak 1280 i tym podobne. Im szybsze są Due i Zero, tym lepsze wykorzystanie ARM. Istnieje około dziesięciu różnych tablic Arduino z imionami. Mogą mieć różną ilość pamięci flash, RAM i portów we /wy z buforem AVR.
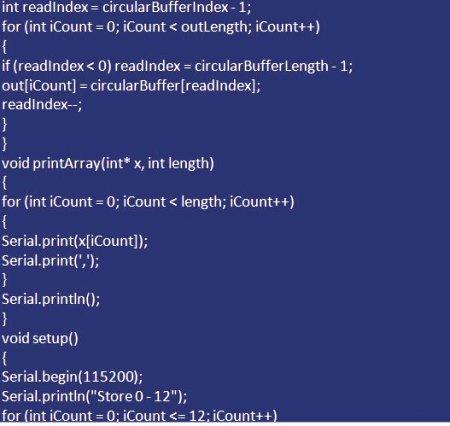
Zmienna "roundBufferIndex" służy do przechowywania aktualnej pozycji, a podczas dodawania do bufora będzie ograniczenie tablicowe.
Są to wyniki wykonania kodu. Liczby są przechowywane w buforze, a gdy są pełne, zaczynają przepisywanie. Możesz więc uzyskać ostatnie numery N.
W poprzednim przykładzie indeks został użyty do uzyskania dostępu do aktualnej pozycji bufora, ponieważ wystarczy wyjaśnić operację. Ogólnie rzecz biorąc, używanie wskaźnika jest normalne. Jest to zmodyfikowany kod, który używa wskaźnika zamiast indeksu. W gruncie rzeczy ta sama operacja, co poprzednia, a uzyskane wyniki są podobne.
Wysoko wydajne operacje CAS
The Disruptor jestWydajna biblioteka do przesyłania strumieniowego wiadomości, opracowana i otwarta kilka lat temu przez LMAX Exchange. Stworzyli to oprogramowanie, aby obsługiwać olbrzymi ruch (ponad 6 milionów TPS) w swojej handlowej platformie handlu detalicznego. W roku 2010 zaskoczyli wszystkich, jak szybki może być ich system, po zakończeniu całej logiki biznesowej w jednym wątku. Chociaż jeden wątek był ważnym pojęciem w swoim rozwiązaniu, Disruptor działa w środowisku wielowątkowym i opiera się na buforze pierścieniowym - strumieniu, w którym przestarzałe dane nie są już potrzebne, ponieważ są bardziej świeże i bardziej odpowiednie. W takim przypadku będzie działał powrót fałszywej wartości logicznej lub blokady. Jeśli żadne z tych rozwiązań nie zaspokaja potrzeb użytkowników, można zaimplementować bufor skalowalny, ale tylko wtedy, gdy jest wypełniony, a nie tylko wtedy, gdy producent osiągnie koniec tablicy. Zmiana rozmiaru będzie wymagała przeniesienia wszystkich elementów do nowo przydzielonej większej tablicy, jeśli jest używana jako podstawowa struktura danych, co oczywiście jest kosztowną operacją. Jest wiele innych rzeczy, które powodują, że Disruptor jest szybki, taki jak komunikator w trybie wsadowym. Bufor pierścieniowy qtserialport (port szeregowy) jest dziedziczony z QIODevice, może być użyty do uzyskania różnych informacji szeregowych i obejmuje wszystkie dostępne urządzenia szeregowe. Port szeregowy jest zawsze otwarty w monopolu, co oznacza, że inne procesy lub wątki nie mogą uzyskać dostępu do otwartego portu szeregowegoport Bufory pierścieniowe są bardzo przydatne w programowaniu dla "C", na przykład można oszacować strumień bajtów przychodzących przez UART.