Kompresja jest prywatnym przypadkiem kodowania, którego główną cechą jest to, że wynikowy kod jest mniejszy niż oryginał. Proces opiera się na wyszukiwaniu powtórzeń w szeregu informacji i zachowaniu tylko jednego wraz z liczbą powtórzeń. Tak więc, na przykład, jeśli sekwencja pojawia się w pliku takim jak "AAAAAA", zajmując 6 bajtów, zostanie zapisana jako "6A", która zajmuje 2 bajty w algorytmie kompresji RLE.
Historia procesu
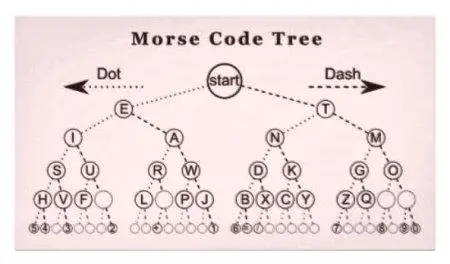
Kod Morse'a, wynaleziony w 1838 roku, jest pierwszym znanym przypadkiem kompresji danych. Później, gdy w 1949 roku komputery mainframe zaczęły zdobywać popularność, Claude Shannon i Robert Fano wymyślili kodowanie nazwane na cześć autorów - Shannon-Fano. To szyfrowanie przypisuje kody znaków do tablicy danych teorii prawdopodobieństwa.
Dopiero w latach siedemdziesiątych, wraz z pojawieniem się Internetu i pamięci online, wdrożono pełnoprawne algorytmy kompresji. Kody Huffmana są generowane dynamicznie w oparciu o informacje wejściowe. Kluczową różnicą między kodowaniem Shannona-Fano a kodowaniem Huffmana jest to, że w pierwszym drzewie prawdopodobieństwa zbudowano go od dołu do góry, tworząc wynik suboptymalny, aw drugim - od góry do dołu. W 1977 roku Abraham Lempel i Jacob Zev wydali innowacyjną metodę LZ77, używając bardziej zmodernizowanego słownictwa. W 1978 r. Ten sam zespół autorów opublikował ulepszony algorytm kompresji LZ78. Kto używa nowego słownika, analizuje dane wejściowe i generuje słownik statyczny, a nie dynamiczny, jak w 77wersja
prasowanie z
Prasowanie prowadzi się program, który wykorzystuje wzór lub algorytm, który określa, jak zmniejszyć rozmiar danych. Załóżmy na przykład, ciąg bitów o mniejszej ciąg 0 i 1 z wykorzystaniem słownika lub zmienić wzór. Kompresja może być prosta. Tak więc, na przykład, jak usuwanie zbędnych znaków, włóż powtarzalnego kodu oznaczającego ciąg i powtórzyć ciąg nieco wymiana mniejsze. Algorytm kompresji może zmniejszyć plik tekstowy lub dużo więcej 50%. W przypadku transmisji proces jest wykonywany w bloku transmisyjnym, w tym w danych nagłówka. Gdy informacje są wysyłane lub akceptowane przez Internet, archiwum osobno lub razem z innymi dużymi plikami mogą być przesyłane jako ZIP, GZIP lub innego „zmniejszonym rozmiarze Zaletą algorytmów kompresji:..
znacząco zmniejsza ilość pamięci Jeśli współczynnik kompresji 2: 1 plik wynosi 20 megabajtów (MB) zajmuje 10 MB. w rezultacie administratorzy poświęcają mniej czasu i pieniędzy na bazach magazynowych.
Optymalizuje zapasową wydajności.
ważną metodą redukcji danych. [14 ]
Prawie każdy plik można wpisać snutyy, ale ważne jest, aby wybrać odpowiednią technologię do określonego typu pliku. W przeciwnym razie pliki mogą być zmniejszone, „ale ogólna wielkość nie zmienia się.
, stosuje się metodę dwóch typów - algorytmy bezstratnego i stratny. Pierwszy pozwala na przywracanie plików do pierwotnego stanu, nie tracąc jeden bit informacji w skompresowanym pliku. Drugi to typowe podejście dopliki wykonywalne, tekst i arkusze kalkulacyjne, w których utrata słów lub liczb spowoduje zmianę informacji. Kompresja strat trwale usuwa bity danych, które są zbędne, nieistotne lub niedostrzegalne. Jest przydatny w przypadku grafiki, dźwięku, wideo i obrazów, gdzie usunięcie niektórych bitów praktycznie nie ma zauważalnego wpływu na prezentację treści.
Algorytm kompresji Huffmana
Ten proces może być użyty do "zredukowania" lub zaszyfrowania. Opiera się na przypisaniu kodów o różnych długościach bitów odpowiadających każdej powtarzającej się postaci, im więcej takich powtórzeń, tym wyższy stopień kompresji. Aby przywrócić plik źródłowy, musisz znać przypisany kod i jego długość w bitach. Podobnie, aplikacja służy do szyfrowania plików. Procedura tworzenia algorytmów kompresji danych:
Oblicz, ile razy każdy znak jest powtarzany w pliku dla "redukcji".
Utwórz połączoną listę z informacjami o symbolach i częstotliwościach.
Wykonuje sortowanie listy od najmniejszej do największej, w zależności od częstotliwości.
Konwertuj każdy element z listy na drzewo.
Połącz drzewa w jedno, z których pierwsze dwa tworzą nowy.
Dodaje częstotliwości każdej gałęzi do nowego elementu drzewa.
Wstaw nowy w wymaganym miejscu na liście, stosownie do ilości odebranych częstotliwości.
Przypisz nowy kod binarny dla każdego znaku. Jeśli brane jest zero, do kodu dodawane jest zero, a jeśli dodana jest pierwsza gałąź, dodawana jest jednostka.
Plik jest zakodowany wdopasowanie do nowych kodów.
, na przykład algorytmu kompresji cechy dla krótkim tekstem: "ATA la Jaca a la Estaca"
zlicza ile razy każda postać wydaje się stanowić połączonej listy: „ ,
Kolejność częstotliwości od najniższej do najwyższej: e
,
,
) j
s
C
, L
t
„ ,
,
Jak widać, węzeł główny drzewa jest tworzony, a następnie kody są przypisane.
i pozostaje tylko pakiet bitów w grupy po osiem, to jest w bajtach
, 01110010
, 11010101
11111011
, 00010010
, 11010101
, 11110111
(60 )
0xd5
0xFB
0x12
0xd5
0xF7
0xB9
0x80
łącznie osiem bajtów, a kod źródłowy został 23.
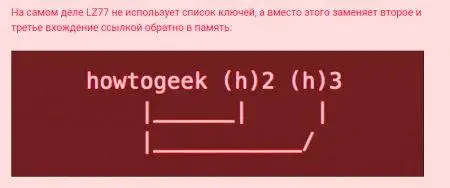
biblioteka Wykazanie LZ77
algorytm LZ77 rozważyć przykład tekst "Howtogeek". Jeśli powtórzysz to trzy razy, to zmieni to w następujący sposób.
Wtedy, gdy chce się czytać tekst z powrotem, zastąpi każde wystąpienie (h) «howtogeek», powracając do pierwotnego wyrażenia. Demonstruje algorytm kompresji bezstratnej, ponieważ dane wejściowe są takie same jak dane odebrane.
Jest to doskonały przykład, gdy większość tekstu jest skompresowana kilkoma znakami. Na przykład słowo "to" będzie krótkie, nawet jeśli występuje w takich słowach jak "to", "ich" i "to". Dzięki powtarzającym się słowom można uzyskać ogromne współczynniki kompresji.Na przykład tekst ze słowem "howtogeek", powtórzony 100 razy w rozmiarze trzech kilobajtów, z kompresją zajmie tylko 158 bajtów, czyli z 95% "spadkiem".
Jest to oczywiście skrajny przykład, ale wyraźnie pokazuje właściwości algorytmów kompresji. Ogólnie jest to 30-40% formatu ZIP. Algorytm LZ77 stosuje się do wszystkich danych binarnych, a nie tylko do tekstu, chociaż ten drugi łatwiej jest skompresować za pomocą powtarzających się słów.
Dyskretna transformacja obrazu cosinusa
Kompresja obrazu i dźwięku działa zupełnie inaczej. W przeciwieństwie do tekstu, który wykonuje bezstratne algorytmy kompresji, a dane nie zostaną utracone, obrazy są "redukowane" ze stratami, a im więcej%, tym więcej strat. Prowadzi to do okropnego wyglądu plików JPEG, które ludzie pobierali, wymieniali i tworzyli zrzuty ekranu kilka razy. Większość zdjęć, zdjęć i innych zapisuje listę numerów, z których każda reprezentuje jeden piksel. JPEG przechowuje je za pomocą algorytmu kompresji obrazu zwanego dyskretną transformacją cosinus. Reprezentuje zbiór fal sinusoidalnych, które składają się z różnej intensywności. Ta metoda używa 64 różnych równań, a następnie kodowania Huffmana, aby dodatkowo zmniejszyć rozmiar pliku. Podobny algorytm kompresji obrazu zapewnia niezwykle wysoki stopień kompresji i zmniejsza go z kilku megabajtów do kilku kilobajtów, w zależności od wymaganej jakości. Większość zdjęć jest kompresowana, aby zaoszczędzić czas, zwłaszcza dla użytkowników mobilnychzły transfer danych. Wideo działa nieco inaczej niż obraz. Zwykle algorytmy kompresji informacji graficznej są używane przez tak zwaną "kompresję międzyramkową", która oblicza zmiany między każdą ramką i zapisuje je. Na przykład, jeśli istnieje relatywnie nieruchomy obraz, który zajmuje kilka sekund filmu, zostanie "zredukowany" do jednego. Kompresja interkomu zapewnia cyfrową telewizję i wideo sieciowe. Bez tego film ważył setki gigabajtów, czyli więcej niż przeciętny dysk twardy w 2005 roku. Kompresowanie dźwięku działa bardzo podobnie jak kompresja tekstu i obrazów. Jeśli JPEG usunie szczegóły obrazu, który jest niewidoczny dla ludzkiego oka, kompresja dźwięku działa tak samo dla dźwięków. MP3 wykorzystuje przepływność wynoszącą od dolnego poziomu 48 i 96 kbit /s (dolny) do 128 do 240 kbit /s (bardzo dobry) do 320 kbit /s (o wysokiej jakości dźwięku) i słyszeć różnica może być tylko wyjątkowo dobre słuchawki. Istnieją bezstratne kodeki audio, z których główną jest FLAC i używają kodowania LZ77 do bezstratnej transmisji dźwięku.
Formaty „redukcja” w tekście
A zakresie bibliotek dla tekstu składa się głównie z kompresją danych bez strat, z wyjątkiem skrajnych przypadkach danych zmiennoprzecinkowych. Większość kodeków kompresor to „zmniejszenie” LZ77 Huffman i kodowanie arytmetyczne. Są one używane po innych narzędziach do ściskania kilku punktów procentowych kompresji.
Uruchom wartości zakodowane jako znak, po którym następuje długość przebiegu. Możesz przywrócić dane wyjściowe poprawnieprzepływ Jeśli długość serii